



The Future Of Post-Training Data?
Post-training Enhancements To Drive Compute Equivalent Gains

Hey friends! I’m Akash, an early stage investor at Earlybird Venture Capital, partnering with founders at the earliest stages.
Software Synthesis is where I connect the dots in software strategy. Please reach out to me at akash@earlybird.com if we can work together!
Current subscribers: 4,550
Back in the last Industrial Revolution, water comes into a machine, you light the water on fire, right, turn it into steam, and then it turns into electrons.
Atoms come in, electrons go out.
In this new Industrial Revolution, electrons come in, and floating point numbers come out.
Just like the last Industrial Revolution, no body understood why electricity is valuable and it’s now sold and marketed as kilowatt hours per dollar…
Now we have ‘million tokens per hour’. That same logic is as comprehensible to a lot of people as the last Industrial Revolution but is going to be completely normal in the next 10 years.
These tokens are going to create new products, new services, enhanced productivity on whole slew of industries, $100tn worth of industries on top of us.
The ‘AI factories’ that will generate these floating point numbers and revolutionise entire industries will require a rearchitecting of data centres worth trillions constructed in the PC-CPU era to become ‘AI factories’.
Philippe Laffonte’s estimate is that all of the c. $100 trillion in capex for the general purpose PC-CPU era will be replaced by an equivalent buildout of accelerated computing infrastructure, whilst David Cahn of Sequoia published a revised $600B question of whether we’ll generate enough revenue to fill the capex hole.
LLMs have catapulted AI to the top of the agenda for C-Suite execs and enterprises have become 3x more efficient in putting models into production; the ratio of logged-to-registered models fell from 16:1 to 5:1 between February 2023 and March 2024 in Databricks’ recent State of Data AI report. Though only 20% of executives are vigilant of the costs of putting AI into production, this number is bound to increase.
Together, usage of the two smallest Meta Llama 2 models (7B and 13B) is significantly higher than the largest, Meta Llama 2 70B. Across Meta Llama 2, Llama 3 and Mistral users, 77% choose models with 13B parameters or fewer. This suggests that companies care significantly about cost and latency.
We’ve already discussed margin wars and Nvidia’s interchange rate before. Inference will surely be a priority, but so will the cost of post-training data needed to scale performance efficiently.
Post-training data’s scaling potential
Given the now well known depreciation of N-1 generations of chips, will we see more enterprises train their own models?
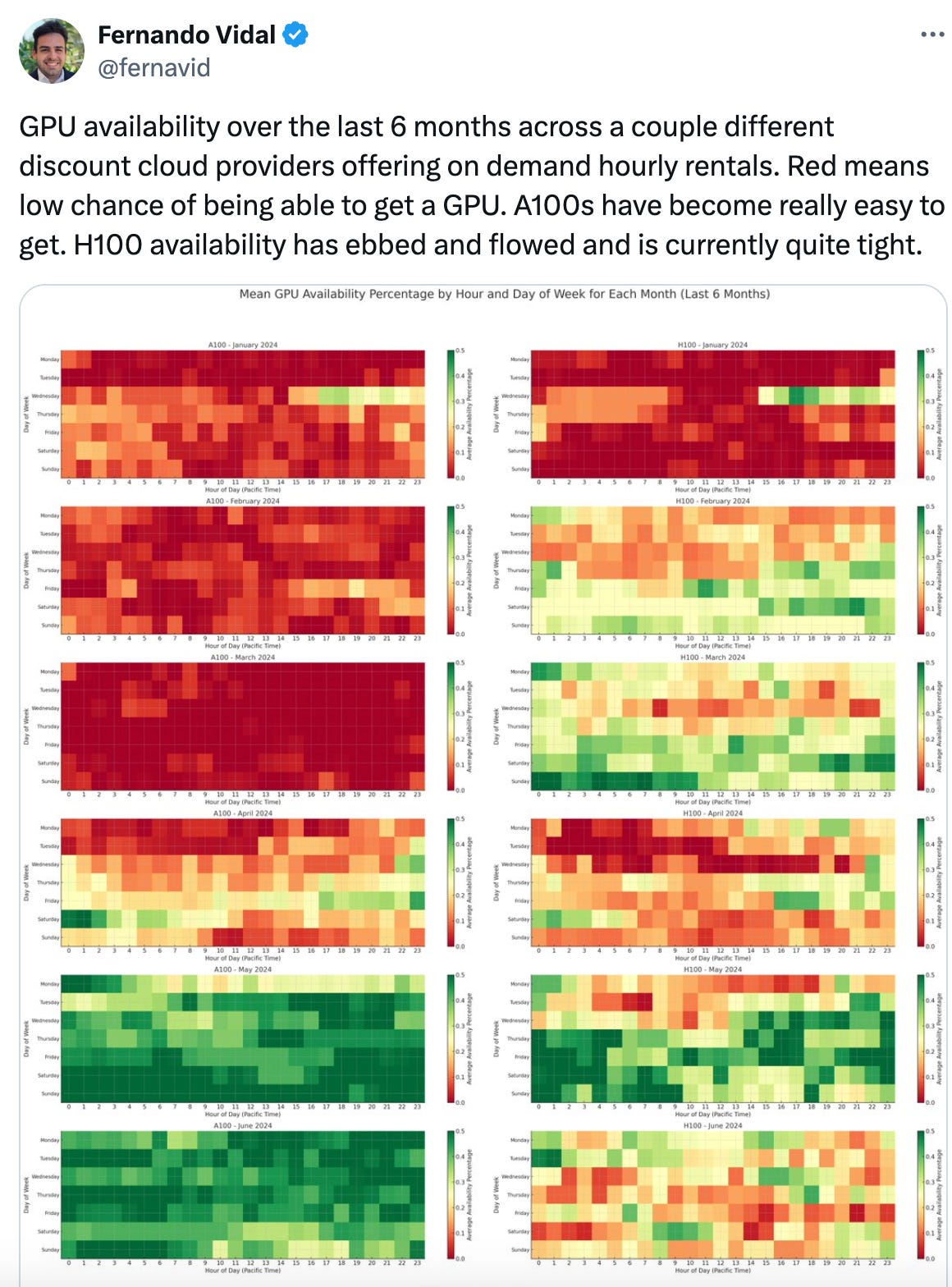
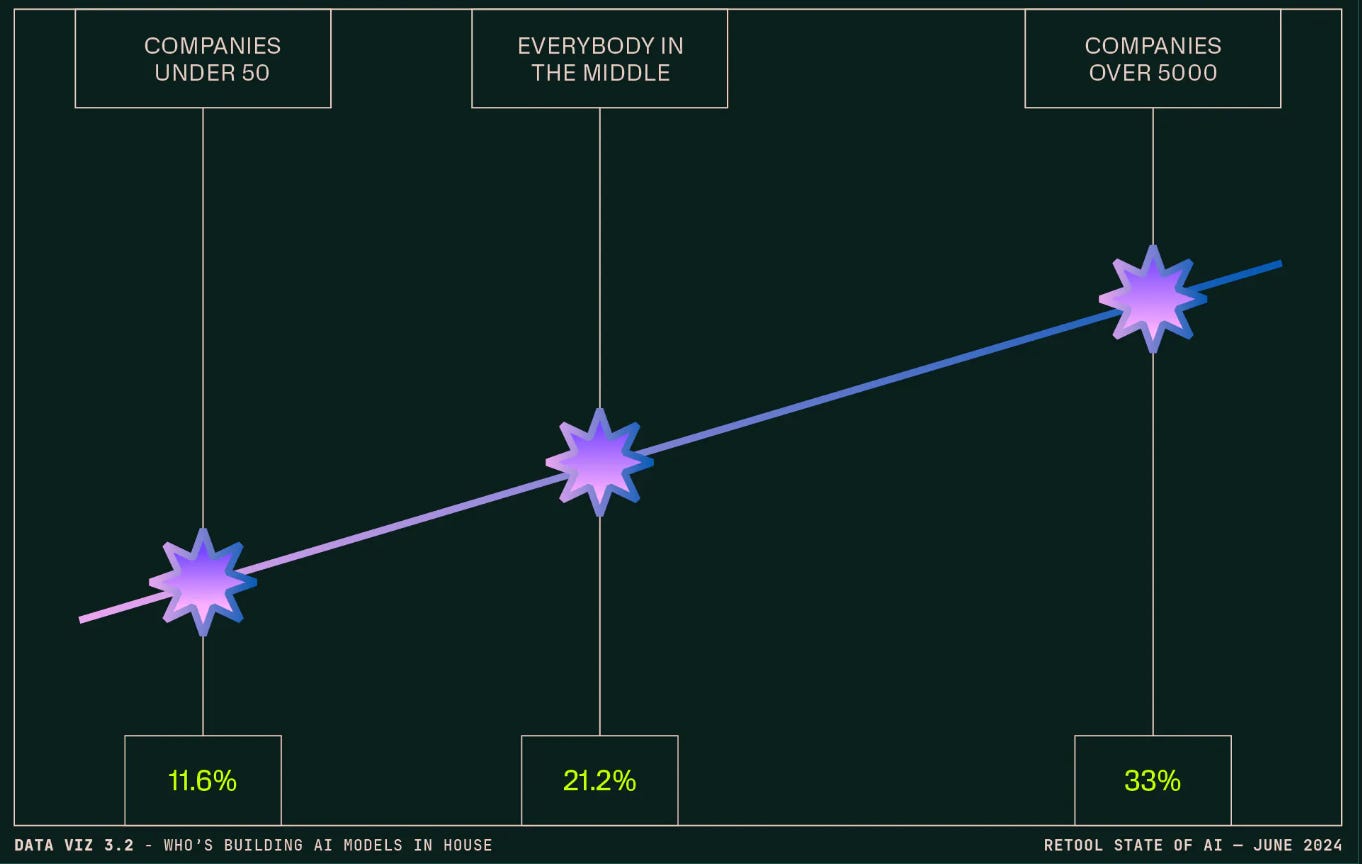
Retool’s survey doesn’t provide enough granularity to discern if the 33% of enterprises exploring in-house model development are simply fine-tuning pre-trained models or training base models from scratch. Just as businesses won’t become IT departments overnight and scrap managed services in favour of running open source software, it’s unlikely that the TCO of pre-training is justified for the vast majority of use cases. This is all of course ignoring the challenge to attract and retain research talent.
Enterprises will rather focus their energies on injecting their private corpuses and customising pre-trained models for specific use cases or domains.
A paper from Epoch AI in December presented results showing that post-training enhancements can deliver up to 30x more efficient scaling of model performance than scaling up compute in pre-training.
CEG is defined to be the amount by which pre-training compute must be scaled up to improve benchmark performance by as much as the enhancement
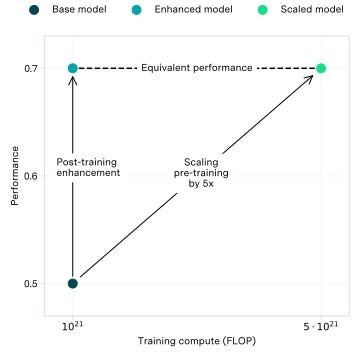
Last week, researchers at OpenAI (including recently departed Jan Leike) released a paper underlining the eventual limitations of RLHF as models continue developing. The paper shows that a critic model trained via RLHF to detect code bugs is 30x more efficient than scaling pre-training compute for the same results.
‘Contractors indicate that CriticGPT (RL only) misses inserted bugs substantially less often than ChatGPT. Training a larger model also reduces the rate at which inserted bugs are missed, but naive extrapolation implies that to match the performance of CriticGPT (RL only) on this distribution would require around a 30x increase in pre-training compute.’
The authors go on to say that the future of post-training may be a combinations of human contractors and models:
Critics can have limitations of their own, including hallucinated bugs that could mislead humans into making mistakes they might have otherwise avoided, but human-machine teams of critics and contractors catch similar numbers of bugs to LLM critics while hallucinating less than LLMs alone.
If data walls impede the advancement of models, Scale AI’s 200% annual growth to a projected $1.4bn ARR EOY 2024 and c. $14bn valuation is far more palatable as the data foundry that helps unblock continued scaling.
Speaking to Ben Thompson about the challenge of replicating Scale’s operational infrastructure for data collection, CEO Alexandr Wang said:
I think there’s a huge amount of cost that’s gone into building this, and it’s very difficult to fully replicate exactly what we’ve built, and I don’t think a lot of our customers are super motivated to do that.
The market for alignment-as-a-service aims to make data collection as easy launching a job on a cluster.
AI-native applications are already hiring expert labellers - vertical AI companies are rely on practitioners solve the last mile problem of quality assurance (to meet service-like SLAs) or are ostensibly the kinds of experts Scale AI would also hire for RLHF. Should enterprises weigh up the TCO of generating high quality data for a specific use case or domain?
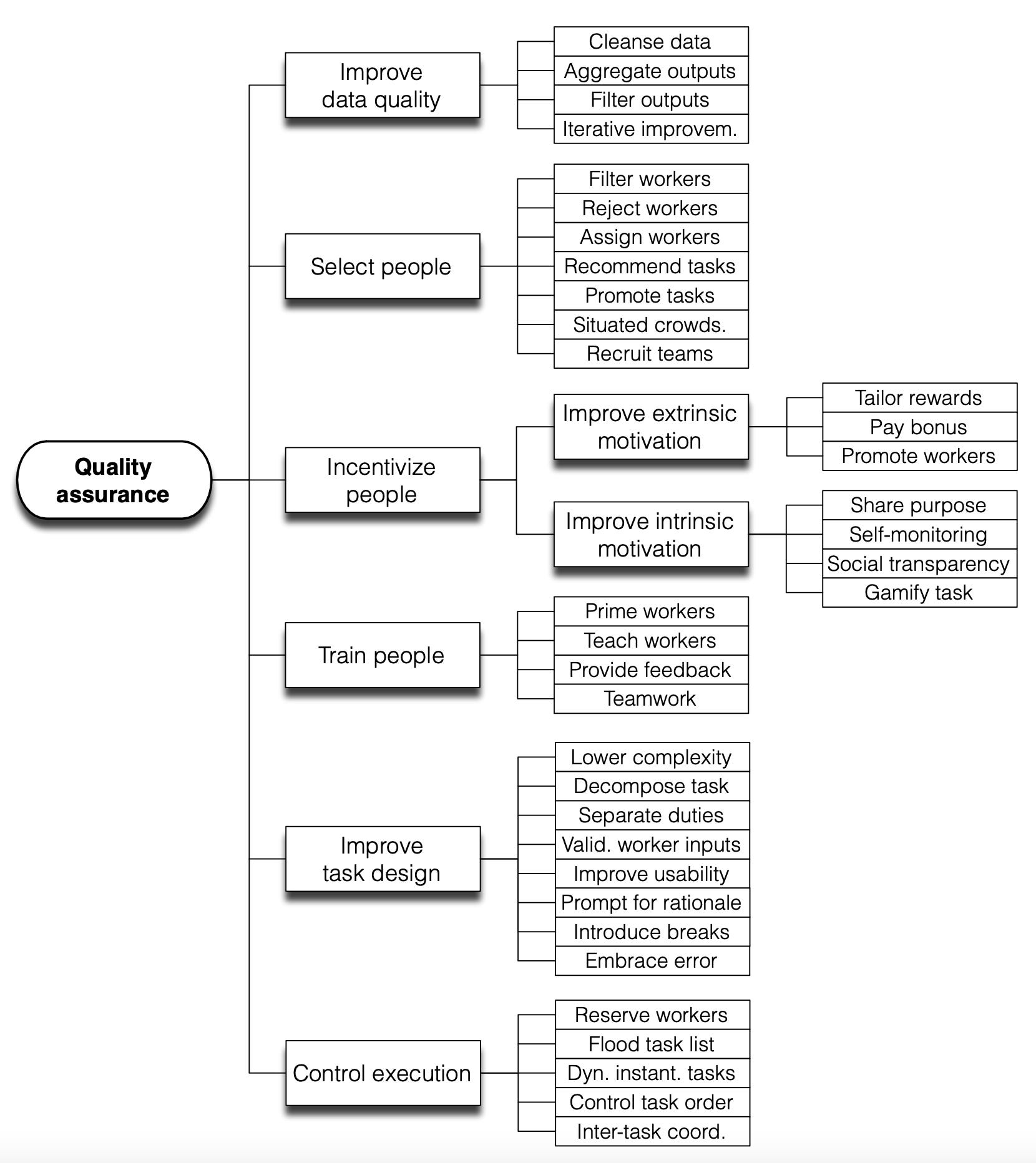
High quality post-training data is one piece of the enterprise AI puzzle.
The engineers behind DBRX (Databricks) and Arctic (Snowflake) would argue that the biggest leaps in performance come from imbuing base models with relevant context from private enterprise corpuses that just need to be preprocessed, especially in a world where the majority of use cases rely on RAG.
This "frontier data"—expert knowledge, workflow logs, multimedia assets, and so on—represents far more granular and domain-specific information than what's publicly available on the internet. To put this in perspective, JPMorgan reportedly has 150 petabytes of data: a whopping 150 times the size of the dataset used to train GPT-4.
By open sourcing best-in-class small models, the data lakehouses are (like Meta) looking to commoditise their complement (the models) and drive up consumption of compute and storage.
High quality post-training data and enterprise corpuses of private data will both be key to realising the trillions of dollars in value creation.
Charts of the week
Enterprises are beginning to optimise hardware for inference workloads

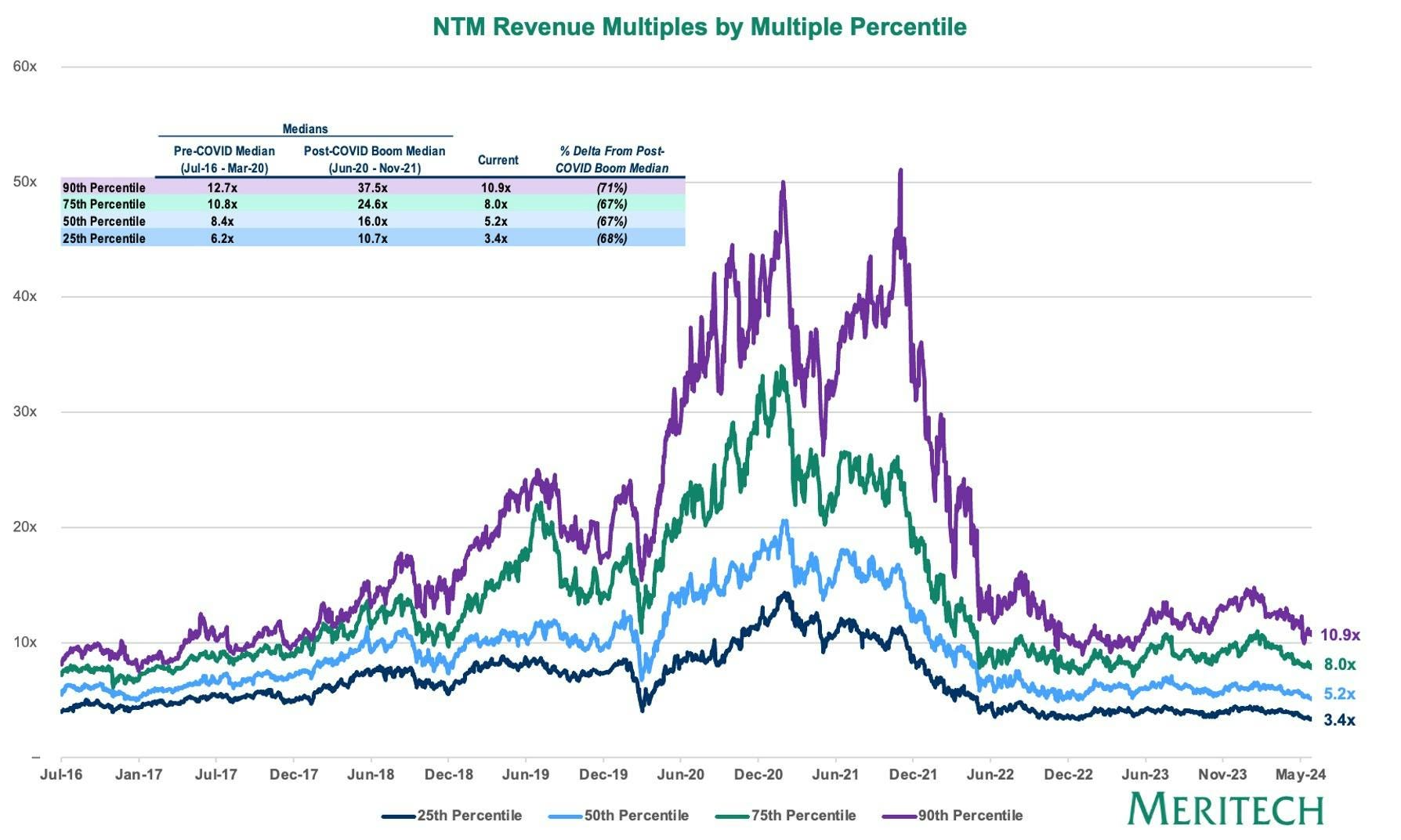
Multiples remain depressed relative to pre-COVID levels
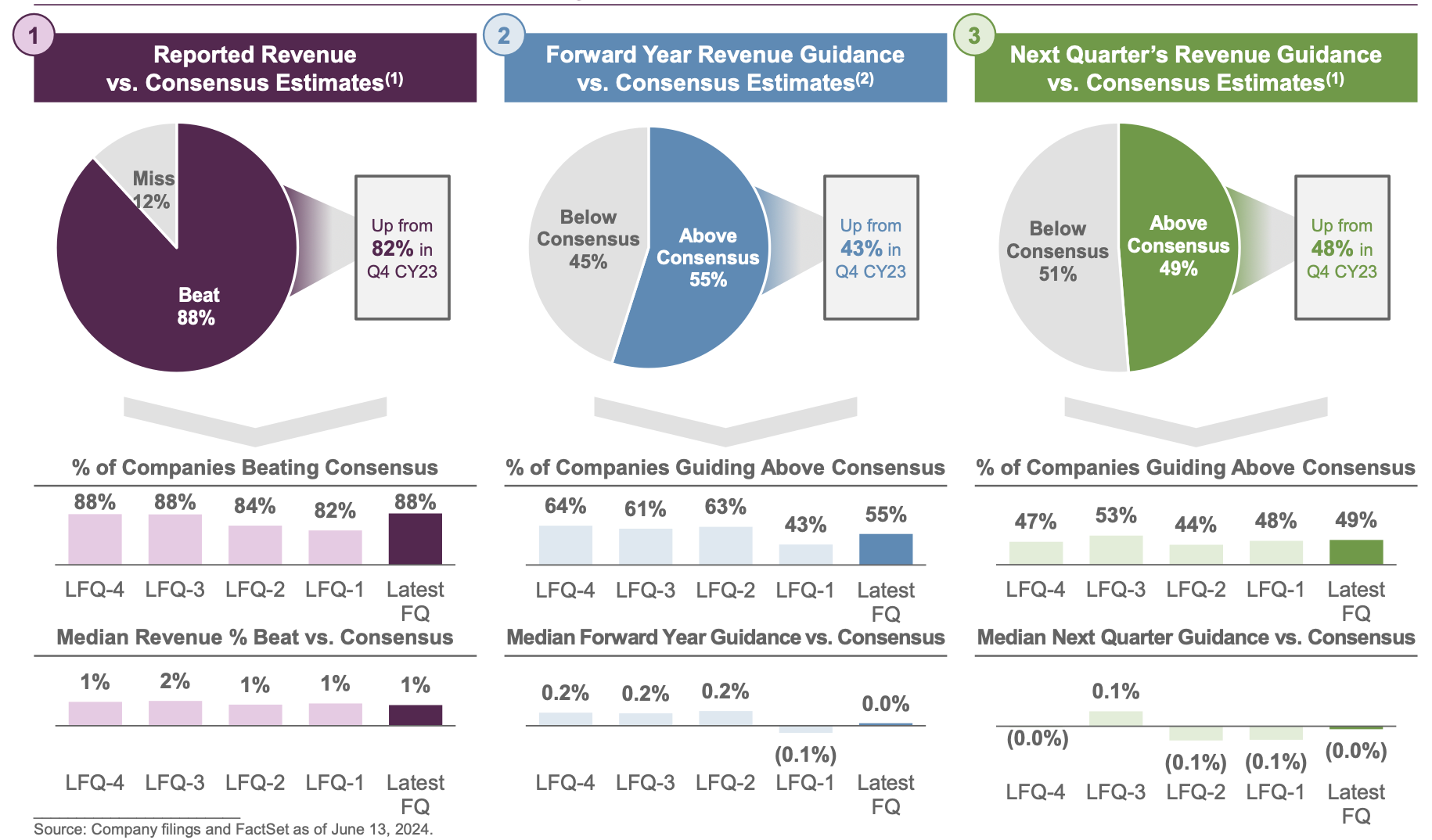
Forward guidance gives a rosier picture
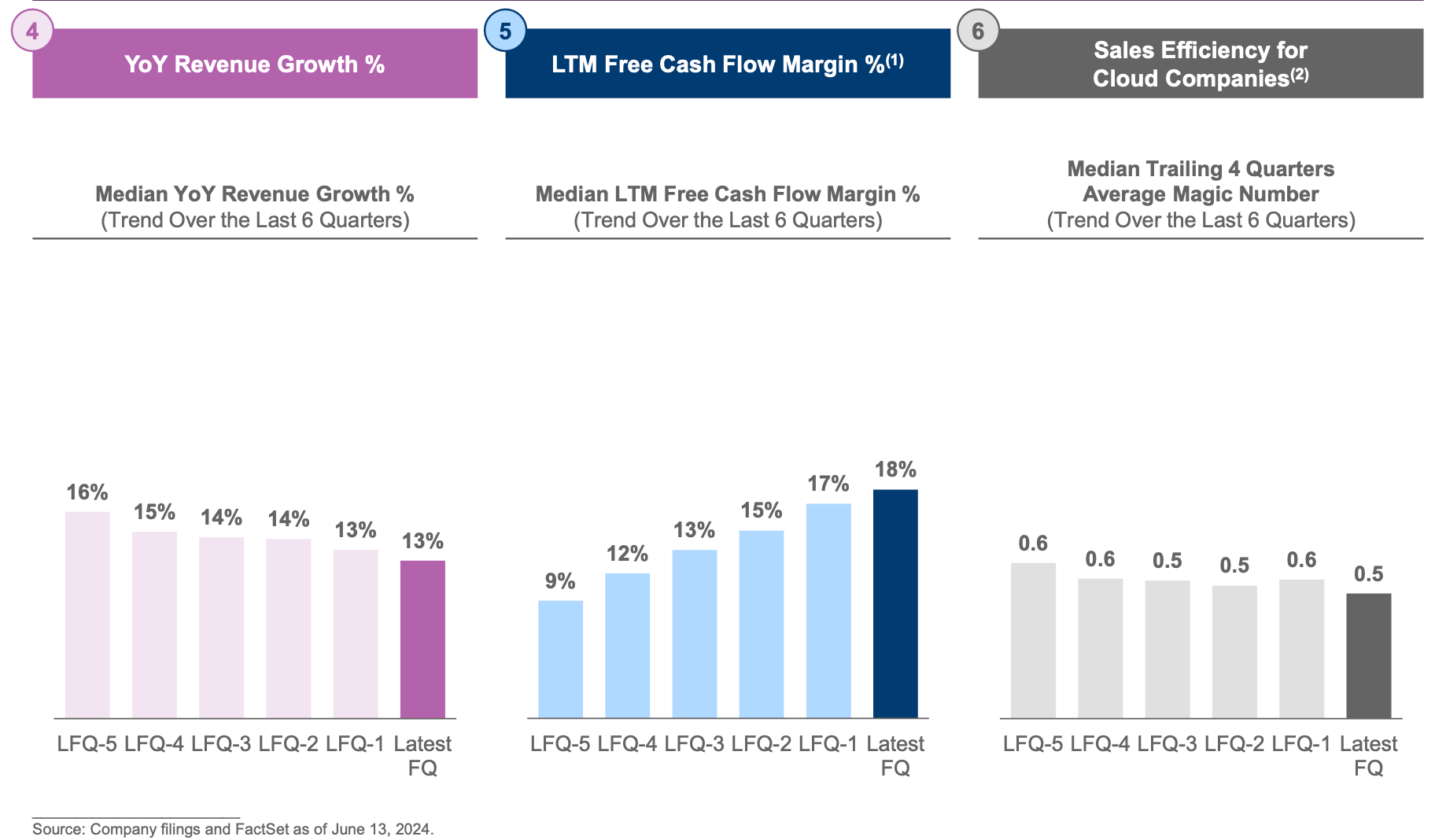
Despite no green shoots in Q1 earnings
Curated Content
Benchmarking Multi Product Penetration in Software by
Goldilocks Agents by Sonya Huang and Pat Grady
Databricks vs. Snowflake: What their rivalry reveals about AI's future by
AI Software Pricing by Gokul Rajaram
In defense of seat based pricing by Jared Sleeper
Quote of the week
‘Many of the things we’ve mentioned, including sports and investing, have large luck components involved. It makes sense for people to look at outcomes. They’re objective and quantifiable, and sometimes they’re audited, but of course, if it’s probabilistic, you can see cases where a good decision-making process is going to lead to a bad outcome simply because of the role of bad chance. And likewise, and I think more difficult, you can have a bad process that leads to a good outcome. what we do know is that over long periods of time, people who make good decisions process-wise end up doing well, ultimately, in outcomes. So the point is: don’t dwell too much on the outcomes because you may be looking at noise or luck. Rather, focus a lot on the process, because you can be assured in the long haul that people with those good processes are ultimately going to do well.’
Thank you for reading. If you liked it, share it with your friends, colleagues, and anyone that wants to get smarter on startup strategy. Subscribe below and find me on LinkedIn or Twitter.