



Extrapolating hardware developments in AI
Supercomputers sited on nuclear power plants to reach GPT-6
Hey friends! I’m Akash, an early stage investor at Earlybird Venture Capital, partnering with founders across Europe at the earliest stages.
I write about software and startup strategy - you can always reach me at akash@earlybird.com if we can work together. I’d love to hear from you.
Current subscribers: 4,330
Last week we hosted several AI founder friends in our London office. There was great diversity in the room, with founders building companies up and down the stack, from infra to applications. We were lucky to be joined by Nick Cochran of Databricks, a friend and former guest of the blog.

Topics discussed ranged from:
With the depreciation in the cost of training base models, what % of enterprises will opt for this? As a corollary, what number of tokens will be needed for the SLMs these enterprises will look to train?
How is Databricks positioned to win AI mandates from enterprises with open sourcing models like DBRX and the MosaicML offering?
What verticals will disproportionately opt for self-hosting models, given concerns over data security and privacy?
There may have been split opinions on these topics, but one thing everyone had in common was the importance of the founder learning rate.
I often refer to the importance of product velocity and momentum as 🔑 indicators of early success for a startup but often overlooked is the rate of founder learning. When it comes the search for PMF, founder learning is often manifested in the speed to hone the core value proposition and pitch as the best founders are able to find signal from noise and iterate quickly and multiple times before PMF.
Given the sheer speed of developments in the wider AI ecosystem, founders must continuously adapt to developments around them, internalising the implications for their products, business model and GTM. To the next one!
Extrapolating to the future
Morgan Stanley recently put out an excellent note extrapolating hardware and software developments in AI, with clear implications for AI market structures and companies in the next few years.
Jensen Huang’s unveiling of the Blackwell generation of GPUs came with the remarkable performance gain of slashing power consumption by up to 75% to train large models.

If we extrapolate the gen-on-gen gains into the future, we’re likely to see a sharp decline of 50% in the cost of compute power for every generation of Nvidia chips:

This will have significant implications for the proliferation of SLMs.

On the Large Language Model end, the authors suggest we’ll see supercomputer clusters developed in close proximity to nuclear power plants, for the following reasons:
Obviates the need to the steps required to interconnect to the power grid.
Space/power to build large data centers.
Significant power infrastructure already exists at nuclear power plants.
Nuclear plants have access to large volumes of cooling water.
With Big Tech already spending in the order of $40bn in data centre capex, it’s plausible that the supercomputers needed for LLM+2 (2 generations beyond the frontier today) models will be funded entirely by their own balance sheets.
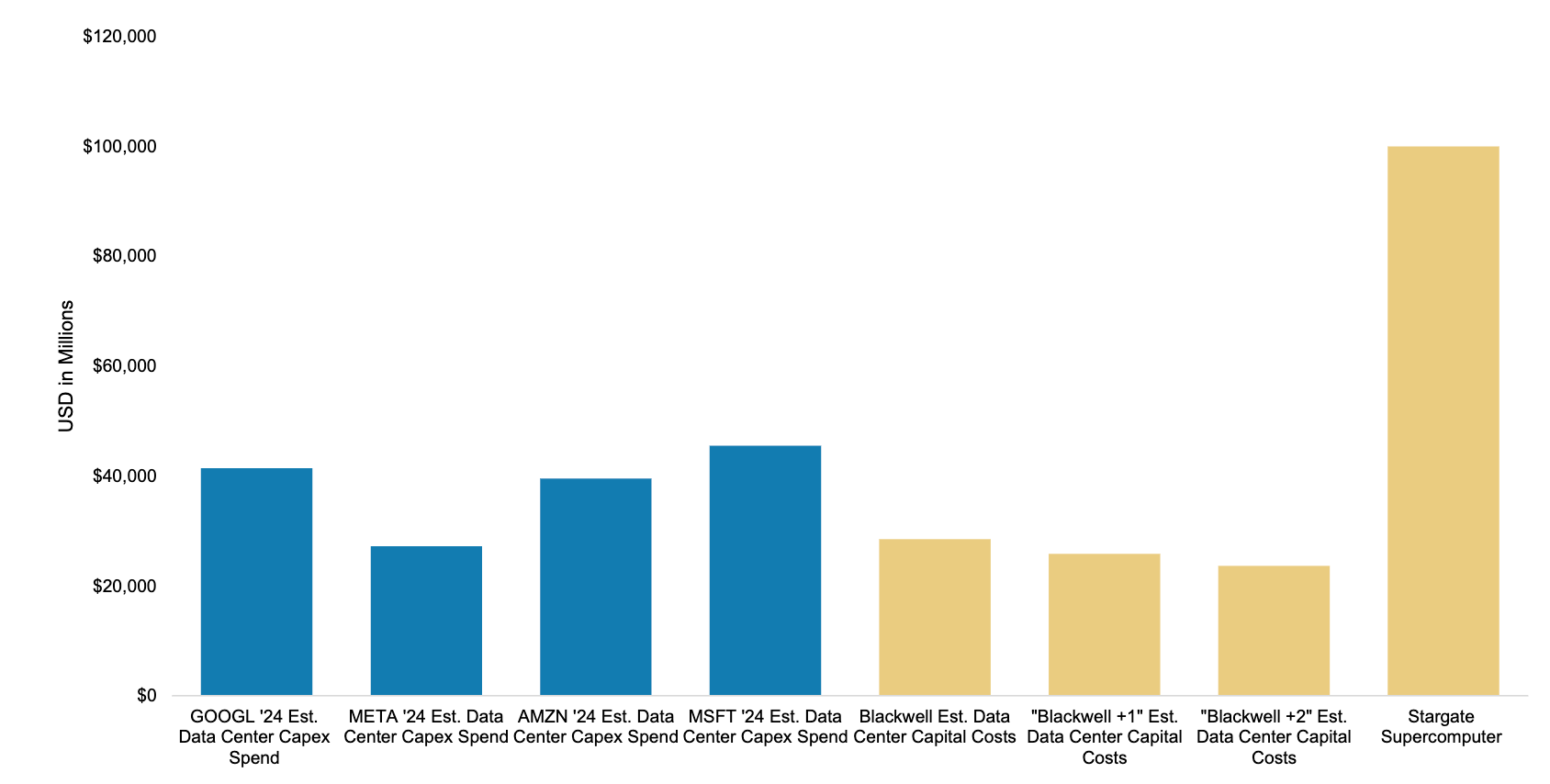
Were we to train GPT-6 today, it would consume the majority of the compute Nvidia will supply in 2024.
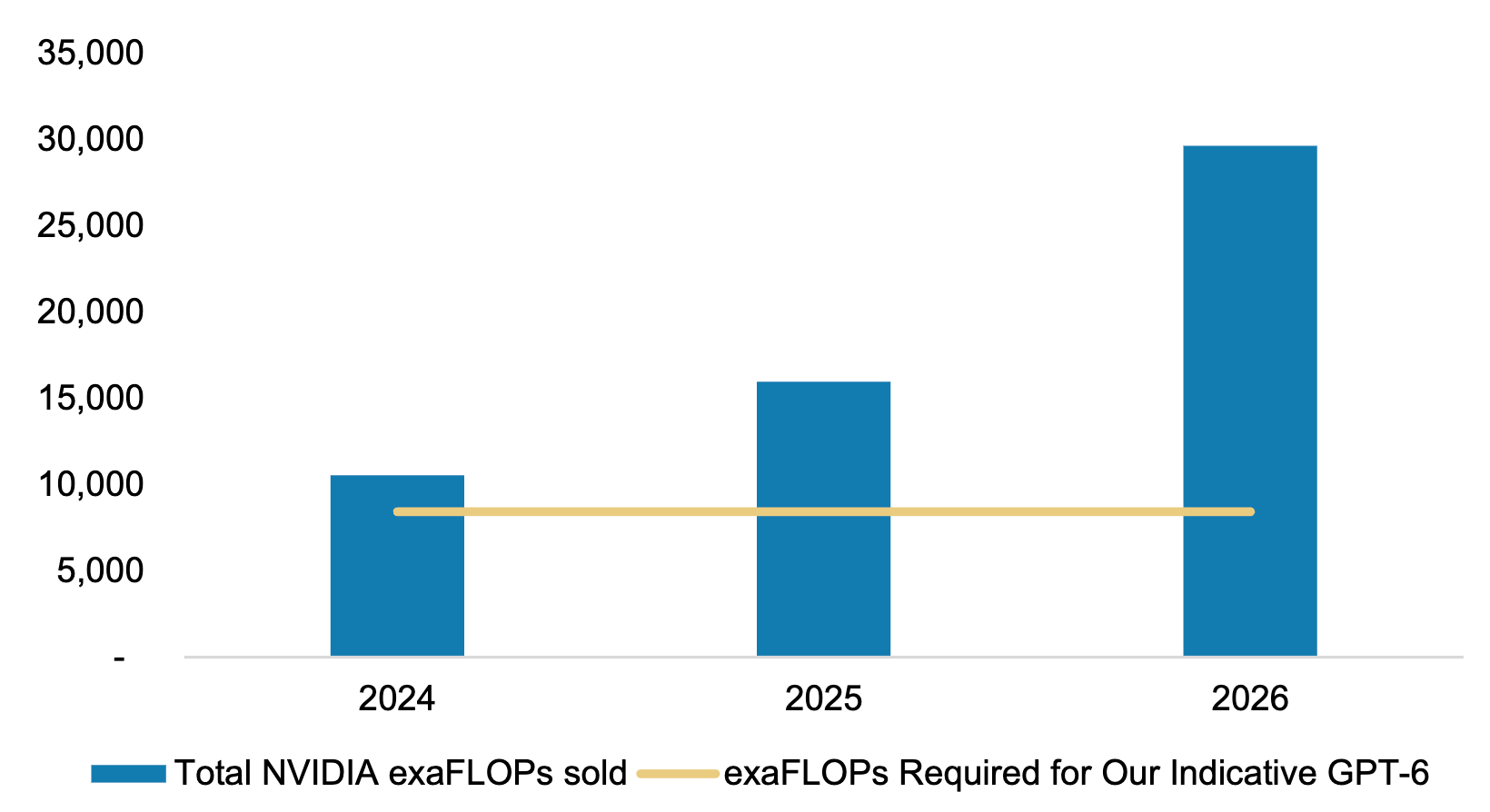
Relative to GPT-4 which took 25,000 A100s and 100 days to train, GPT-5 could see a 5-10x increase in token and parameter sizes and the compute required on current scaling laws would be 25-100x increase, using 200,000-300,000 H100s for 130-200 days.. whilst GPT-6 will command the supercomputers entirely comprised of Blackwell chips and its successors.
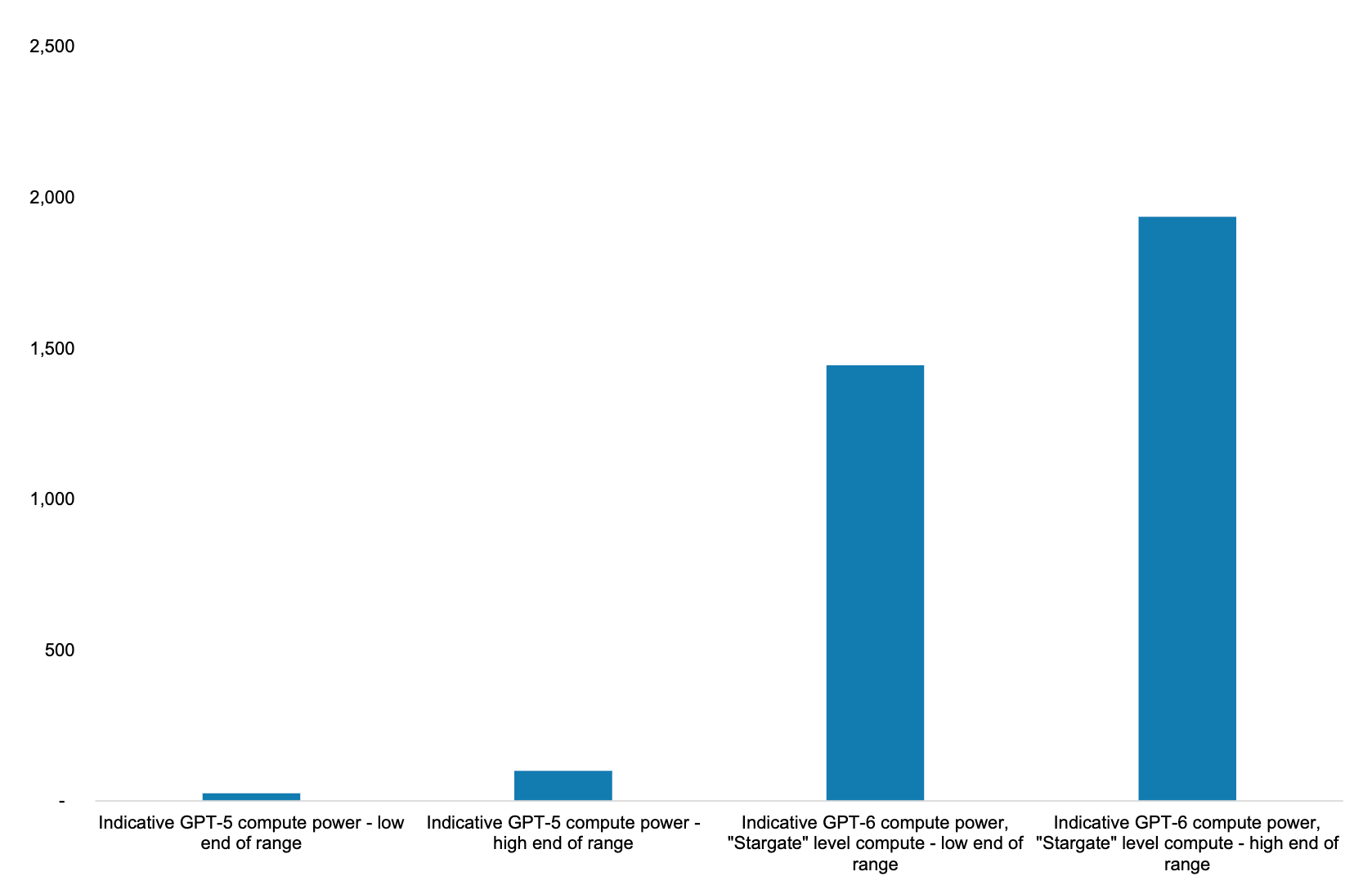
Energy and physical infrastructure is starting to receive more attention as a key bottleneck to model scaling in coming years. In this context, the long-running debate on nuclear energy will inevitably be fanned again. Elad Gil and Sarah Guo discussed this on their podcast last week, entertaining the counterfactual of how geopolitics would have evolved had more countries invested in nuclear energy.
Of the many AI wars (GPUs, data, etc.) that will unfold this century, energy will be among the most important. Europe is in a precarious position, whereas many East Asian countries are well positioned to capitalise on the abundant energy at their disposal.
It’s worth stating that this is only a matter of years away, not decades.
Charts of the week
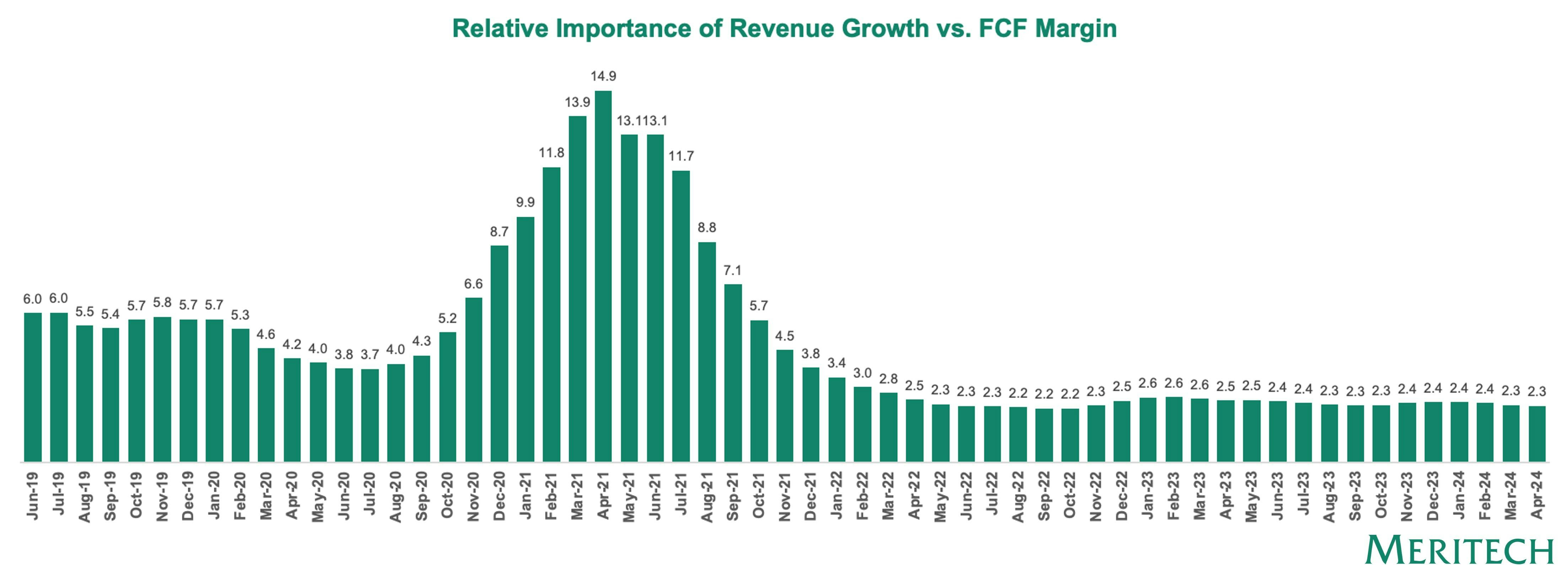
We’ve stabilised at a growth multiplier of c. 2.3x relative to FCF in the public markets
Reading List
OpenAI Is Doomed - Et tu, Microsoft? by SemiAnalysis
Why Adding a 2nd Product Creates The 3 Body Problem by Dharmesh Shah
Who's Going to Consolidate all These Software Companies? by
Where AI is Headed in 2025: A Builder’s Guide by Ashu Garg
Quotes of the week
‘Once again, nearly half of respondents (49%) said that generative AI investments were newly added to the budget. 42% said that the dollars were reallocated from elsewhere (a two percentage-point increase since January). Of those who said generative AI funds were reallocated from elsewhere, business applications were again the most common source, though at a slightly lower rate than in January. Those funding generative AI initiatives by reallocating money from non-IT departments is down by four percentage-points, while those reallocating from Productivity Applications, Advanced Data & Analytics, and Robotic Process Automation have increased vs. three months ago.’
Enterprise Technology Research
Thank you for reading. If you liked it, share it with your friends, colleagues, and anyone that wants to get smarter on startup strategy. Subscribe below and find me on LinkedIn or Twitter.