



Steering Foundation Models In Latent Space
Frontier Interpretability and Programmability for LLMs

Hey friends! I’m Akash, an early stage investor at Earlybird Venture Capital, partnering with founders across Europe at the earliest stages.
Software Synthesis is where I connect the dots on software and startup strategy - you can always reach me at akash@earlybird.com if we can work together!
Current subscribers: 4,420
Last week, we hosted a breakfast for early stage vertical AI founders in London together with our friends Sarah and Tina at Bain Capital Ventures.

We covered a lot of ground, including:
How to think about different GPU providers, what criteria to assess, and when to move on from the hyperscalers
All things people: Chief of Staff, first sales hire, time spent on recruitment, setting an example as a leader (e.g. Wade from Moov)
The job of startups in AI is to find the space between where the foundation model’s off-the-shelf solution ends and the expertise/abilities of the incumbents begin
OpenAI etc won't be able to serve all verticals and both consumer/enterprise use cases. Focus innovation on areas where foundation model improvements make you STRONGER. the notion of a 'wrapper' needs more nuance in terms of the depth of workflow/system design you're doing on top
Counterposition against incumbents by (1) developing proprietary data advantages, having labelling teams in-house (e.g. LegalOps team at EvenUp) and (2) being more radical with UI/UX, even if they have the distribution
Even if improvements in foundation models (e.g. larger context windows) lift the tide for all boats, startups can still win on delivering the solution at lower cost than incumbents
Selling services requires different SLAs; accuracy, latency and coverage matter. Explore different pricing models to ensure steady margin profile.
If you’re a founder, operator or enterprise buyer, let me know if you’d be interested in joining future discussions.
On to today’s post.
Inspecting the internal state of LLMs
We recently discussed how system design (e.g. mix of RAG, prompting, fine-tuning) can address the inherently probabilistic nature of large model outputs. For as long as the scaling laws hold, the profound productivity gains and value creation to be realised will induce further research on how to safely deploy models in production environments.
Much of the discourse around model transparency has centred around training datasets, with a sense of resignation about being able to actually look under the hood of how transformer models internally represent the world after pre-training.
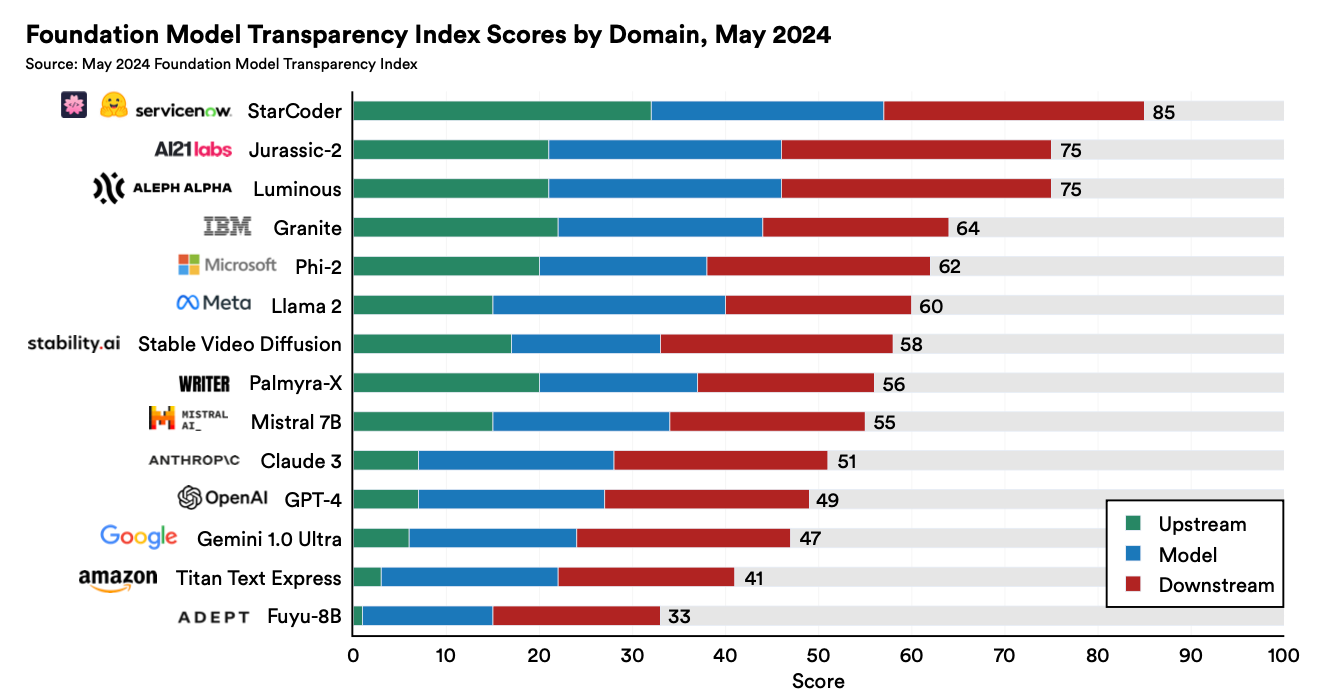
The complexity of studying neural networks as large as the frontier models stems from the fact that each neurons represents many concepts and each concept is represented across many neurons.
Though still nascent, there have been promising developments with sparse autoencoders that are capable of discovering the salient features that large models learn in pre-training. After releasing some promising results back in October, Anthropic unveiled even more intriguing results in May in ‘Mapping the Mind of a Large Language Model’.
Looking at the nearest neighbours of the resulting features, we can see how large language models have imbibed levels of reasoning and intuition that approximate the human brain:
This holds at a higher level of conceptual abstraction: looking near a feature related to the concept of "inner conflict", we find features related to relationship breakups, conflicting allegiances, logical inconsistencies, as well as the phrase "catch-22". This shows that the internal organization of concepts in the AI model corresponds, at least somewhat, to our human notions of similarity.

Martian defines sparse autoencoders as:
SAEs are a type of unsupervised learning model that aims to learn efficient, compressed representations of data.
They do this by training an encoder network to map input data to a sparse latent space, and a decoder network to reconstruct the original data from this sparse representation.
When applied to the task of interpreting neural networks, SAEs are used to learn sparse representations of a model's hidden activations.
The goal is to discover interpretable "features" – directions in the activation space that correspond to human-understandable concepts.
A successful SAE will map the polysemantic activations of the original model, where a single neuron might respond to multiple unrelated concepts, to a monosemantic feature space, where each learned feature corresponds to a single, coherent concept.

Anthropic used ‘dictionary learning’ to capture neuron activations that in combination represented features of large language models:
Just as every English word in a dictionary is made by combining letters, and every sentence is made by combining words, every feature in an AI model is made by combining neurons, and every internal state is made by combining features.
This week, OpenAI announced that they had derived 16 million features of GPT-4 using a sparse autoencoder:
This motivates the use of sparse autoencoders, a method for identifying a handful of "features" in the neural network that are important to producing any given output, akin to the small set of concepts a person might have in mind when reasoning about a situation. Their features display sparse activation patterns that naturally align with concepts easy for humans to understand, even without direct incentives for interpretability.
You can view some of the features derived by OpenAI’s SAE here.
This glimpse inside the mind of large models is consequential for two key use cases: interpretability and programmability.
Interpretability
Even as enterprises and consumers have come to grips with the opacity of large model reasoning, interpretability continues to be the subject of intense research.
Audit trails, citations and other proxies for model output accuracy will go some way to allaying concerns for enterprises, but the desire for interpretability will persist as regulation increases.
Bias detection, for example, will need to be exposed and redressed for decisions that impact end consumer welfare, just as they were for machine learning models used for credit underwriting.
Given the frenzy to regulate AI in Brussels and Washington, we’re undoubtedly going to see more funding for interpretability research.
Programmability
By end of 2024, steering foundation models in latent/activation space will outperform steering in token space ("prompt eng") in several large production deployments.
We’re now in the post-natural language programming era.
Encoder-decoder models have have triggered a Cambrian explosion of productivity and application development, democratising software development well beyond the global software engineer pool of 30 million developers.
The next frontier of programming large language models may well be steering features of large language models.
Claude Sonnet can let people clamp up/down 34 million features ranging from famous people and noun categories to abstract concepts like its ability to keep a secret, code errors and its representation of self.
This is "representation engineering writ large", and probably easy to retrain the SAEs for any set of features you care about.
Anthropic’s article cites a trivial example of feature steering where the ‘Golden Gate Bridge’ feature is amplified, resulting in an inextricable linkage to this feature for future outputs:
Altering the feature had made Claude effectively obsessed with the bridge, bringing it up in answer to almost any query—even in situations where it wasn’t at all relevant.
In each case, the downstream influence of the feature appears consistent with our interpretation of the feature, even though these interpretations were made based only on the contexts in which the feature activates and we are intervening in contexts in which the feature is inactive.
The potential value of feature steering/ablation is distinct from the processing gains of model pruning, quantisation and other compression methods. Feature steering would be particularly valuable for small models where generalisation is less important and excellence at specific tasks or workflows is more valued. The kinds of feature steering that would help include:
Enforcing model output format by removing features for other formats, e.g. when the output is an input for downstream consumption
Modifying knowledge of certain domains to turn general purpose models into more specialised models
Imposing guardrails at the level of features by removing features relating to entities or individuals that should not form part of the model’s knowledge
These are just some hypotheses - in truth, it’s too soon to say what % of this programmability is attainable through prompt engineering and what isn’t. For further reading, Martian have published some interesting research on model mappings and additional techniques for interpretability:
With models cast as programs, we can apply all the tools of software engineering and formal verification to analyze, optimize, and modify them. We can trace their execution, prove properties of their outputs, and compose them into larger systems with guaranteed behavior.
In effect, model mapping turns the opaque, monolithic structure of neural networks into a modular, manipulable substrate, amenable to the full range of human understanding and control.
SAE Scaling
The research on SAEs for model interpretability is nascent but we can see scaling laws with the main parameters being autoencoder latent count (N), sparsity (k), and compute (C).

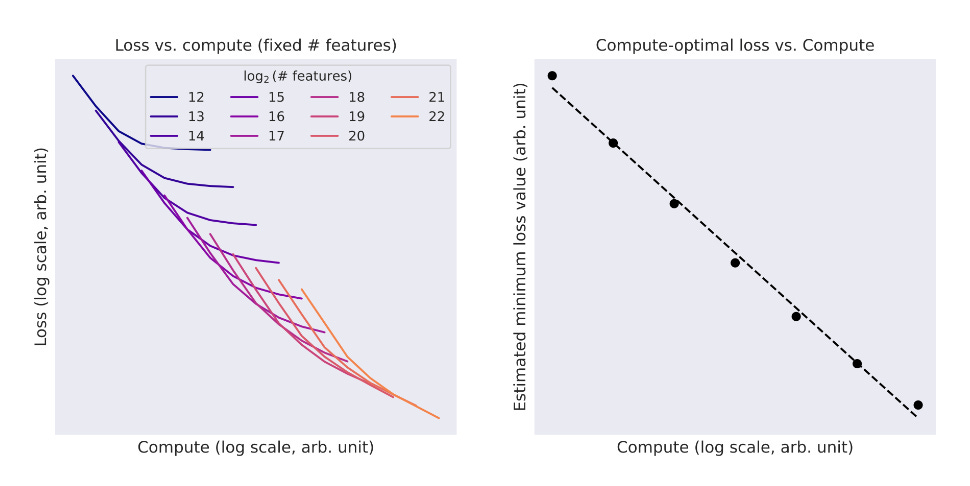
Even though OpenAI scaled their SAE to 16 million features, they conceded that to fully understand the behaviour of GPT-4 would require scaling ‘to billions or trillions of features, which would be challenging even with our improved scaling techniques.’
Open Questions
If feature steering becomes part of the model tuning toolkit, what will be the form factor? Linus Lee of Notion AI asks some very relevant questions to consider:

Will the promise of SAEs really be able to scale with future model generations? At this moment, the results are too limited to extrapolate confidently.
How amenable can features be for end consumers? Anthropic’s focus is on safety related features, hence it’s unlikely that features impacting human alignment would be rendered as editable properties for model consumers.
I’m keen to hear your thoughts!
Market Commentary
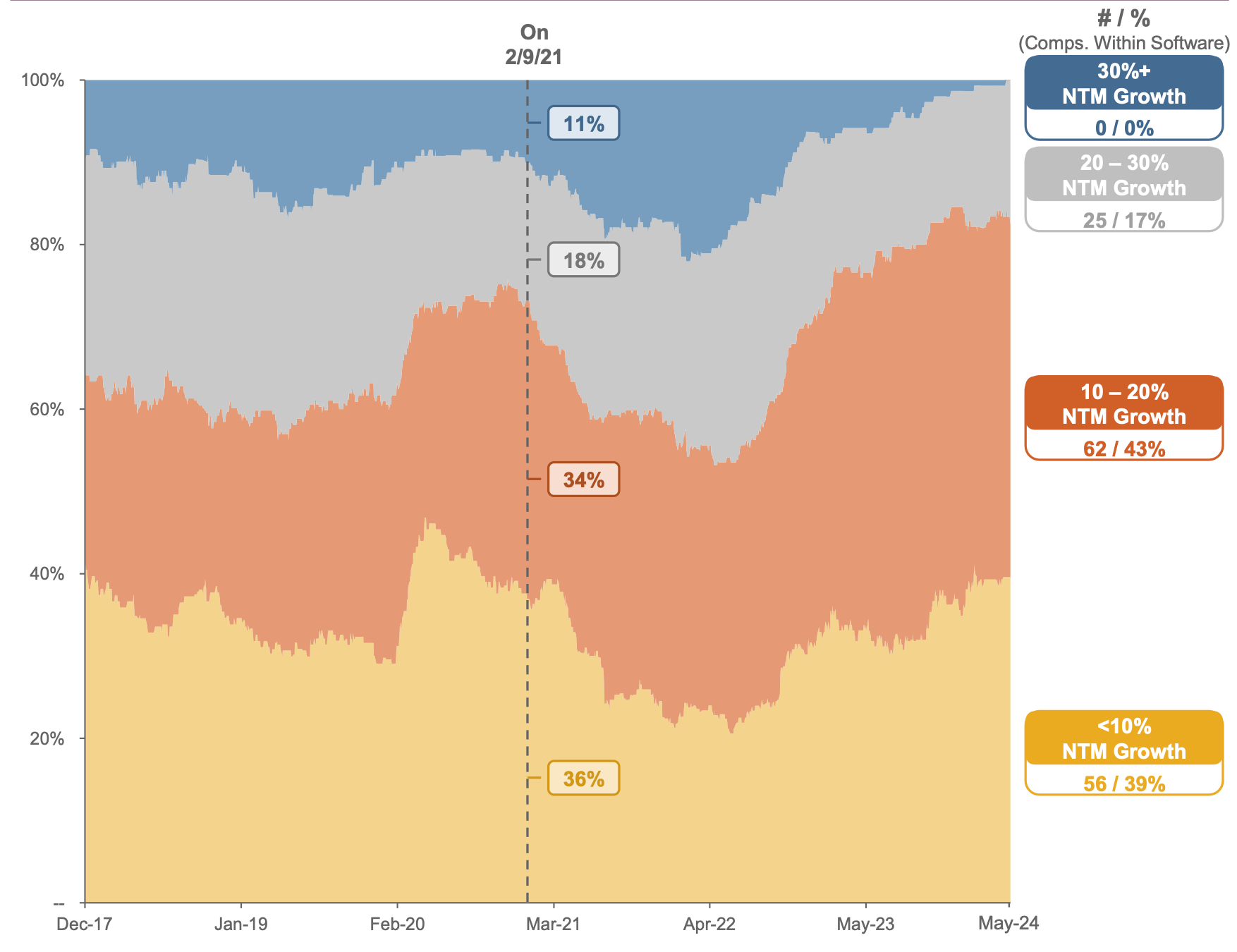
High growth is officially dead. No public software company is projecting to grow > 30% in the next 12 months. It’s tempting to decompose the malaise and pick the AI winners/losers, but it’d be hasty to make declarations about CRM, MDB, and SNOW’s prospects of winning AI budgets.
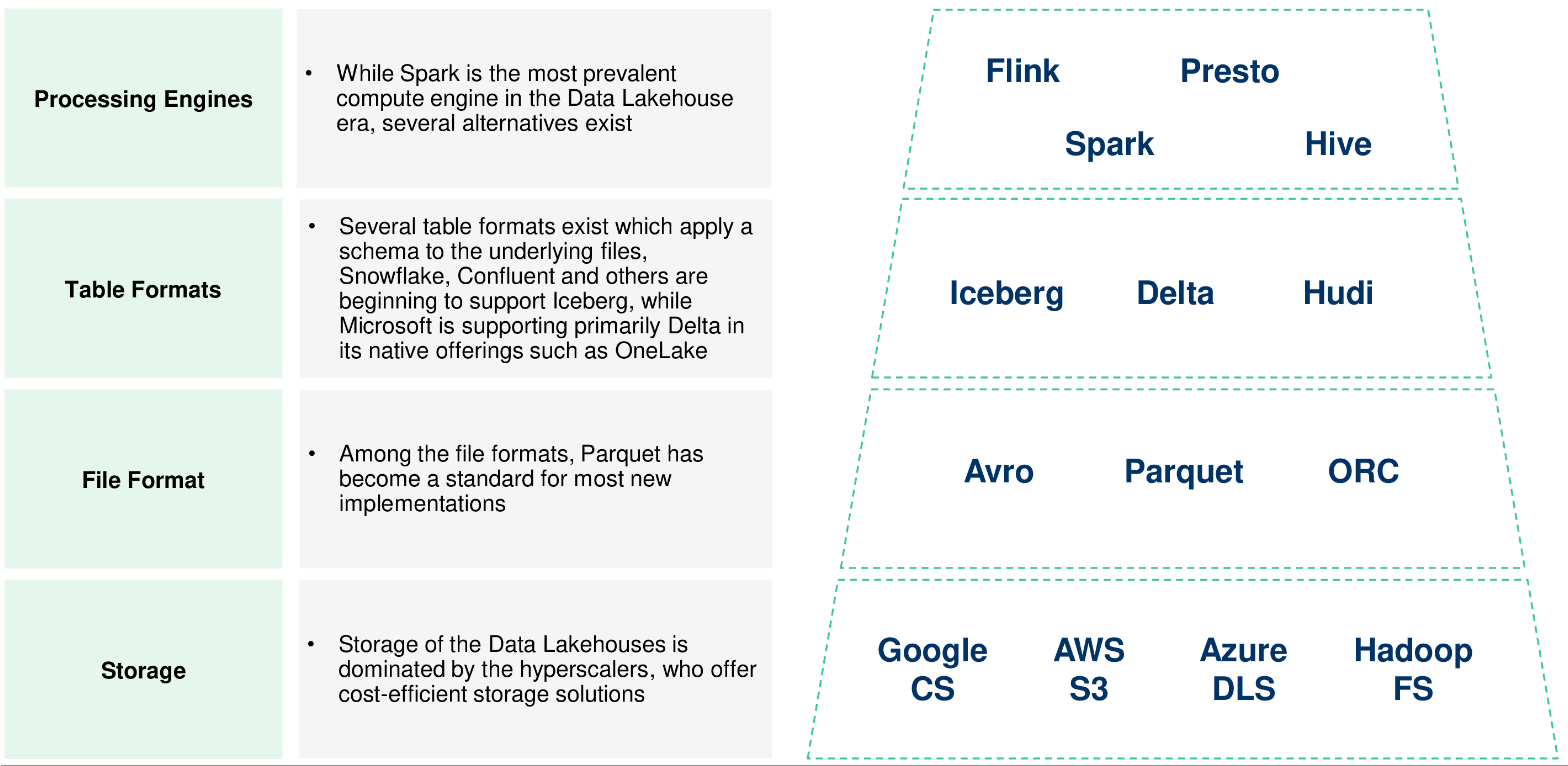
Databricks acquired Tabular, signalling that Iceberg has won the table format war between Delta and Iceberg. Snowflake and Confluent were also rumoured to be bidding. Databricks will incorporate Tabular’s Iceberg capabilities into their Unity Catalog, their ‘unified governance solution for data and AI assets on Databricks’.
Stanford researchers posit that ‘AI research tools made by LexisNexis (Lexis+ AI) and Thomson Reuters (Westlaw AI-Assisted Research and Ask Practical Law AI) each hallucinate between 17% and 33% of the time.’ Against this backdrop, Harvey rumoured to be raising at a $2bn valuation.
Charts of the week
Crowdstrike’s own ‘platformisation’ across Cloud, Identity and SIEM/SOAR has delivered the best growth endurance in the market

Agentic design patterns will become more sophisticated, just as RAG has

Curated Content
Why It's Hard for Small Venture Funds to "Play the Game on the Field" in AI Investing by
Winners Keep Winning | CrowdStrike by
State-Space Models Are Shifting Gears by Sivesh Sukumar
250 European Data Infrastructure startups and what we learned from them by MMC Ventures
Multi-Product, Multiple Choices: How to Determine Product Priorities by Tidemark
Quote of the week
‘Right now, most of the largest funds are focused on AI. Getting anyone to pay attention and care about that company might be hard if you have companies performing well but are not leveraged to an AI thesis. That creates follow-on fundraising risk, and no seed investor or early-stage founder can control the preferences or interests of the next investor. We live in a world where most smaller funds depend on larger, multi-stage funds to invest in the next round to keep their companies going. An added wrinkle is that an investment made in seed today has to be interesting to the venture market that will exist 18-24 months from now; nobody knows what that world will look like, and there is a strong temptation to extrapolate today’s market into the future.’
Thank you for reading. If you liked it, share it with your friends, colleagues, and anyone that wants to get smarter on startup strategy. Subscribe below and find me on LinkedIn or Twitter.