



The RAG Stack: Featuring Knowledge Graphs
Reducing Hallucinations To Make LLMs Production-Grade With Complex RAG


Hey friends! I’m Akash, an early stage investor at Earlybird Venture Capital, partnering with founders across Europe at the earliest stages.
Software Synthesis is where I connect the dots on software and startup strategy - you can always reach me at akash@earlybird.com if we can work together!
Current subscribers: 4,375
This week, I’m excited to be collaborating again with my friend Chia Jeng Yang, co-founder of WhyHow.ai.
Back in 2021, we wrote one of the first pieces on this blog, ‘Rethinking Concentration Risk in Fintech Infrastructure’. You can find more of Chia’s writing at .
Today, we’re covering the emerging stack around RAG (Retrieval Augmented Generation) for enterprise AI, with a focus on knowledge graphs as a key component.
Thank you to Andy Triedman from Theory Ventures and Kwesi Acquay from Redpoint for their feedback!
Enterprise adoption of Generative AI is accelerating with CIOs ready to put use cases into production, but obstacles around model output accuracy and hallucination persist. To that end, enterprises are becoming more sophisticated with how they deploy large models, customising them through fine-tuning and RAG.
RAG will continue to represent an important component of ‘compound systems’, with both fine-tuning and RAG approaches employed for different use cases. Of the trillions in labour cost to be impacted by Generative AI, RAG will play a particularly important role in unlocking a significant proportion of knowledge-intensive tasks that entail information retrieval. As attention shifts to a ‘RAG stack’, knowledge graphs will be a key unlock for more complex RAG and better performance.
Enabling enterprise adoption
We’re still in the early innings of true enterprise adoption of generative AI.
Only a fraction of CIOs have moved LLM projects into production so far.
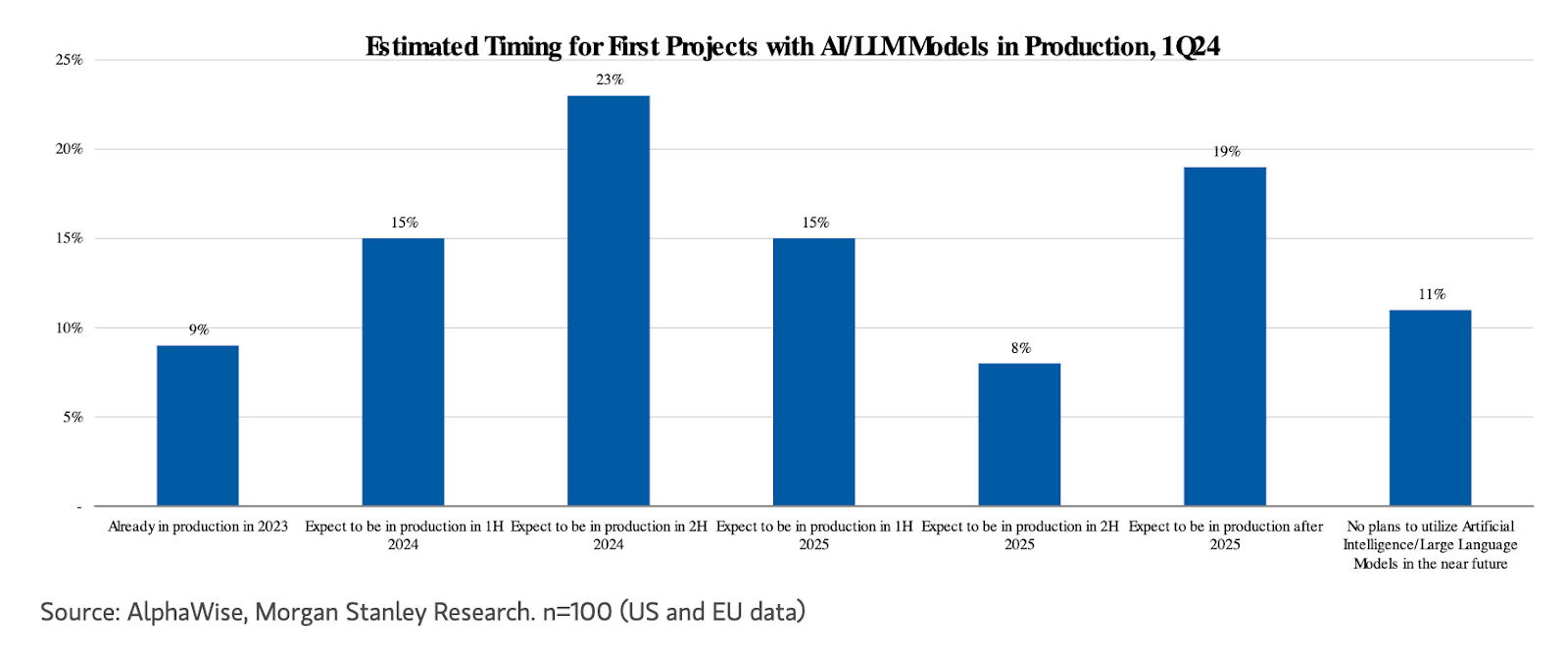
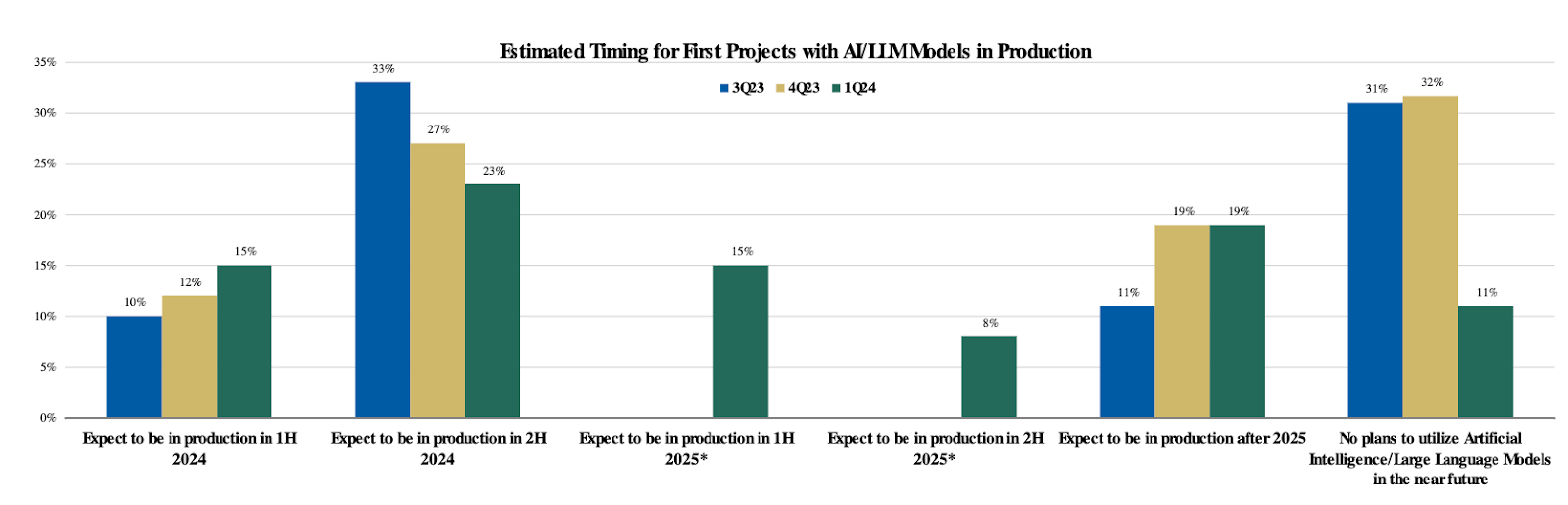
That’s despite concerted boardroom pressure to accelerate AI adoption, with early adopters beginning to transition from experimental innovation budgets to software and labor budgets.
In Q1 2024, 73% of CIOs indicated direct impacts of AI/ML to their investment priorities, which is no surprise given the trillions of dollars in labor costs that can be impacted by Generative AI.
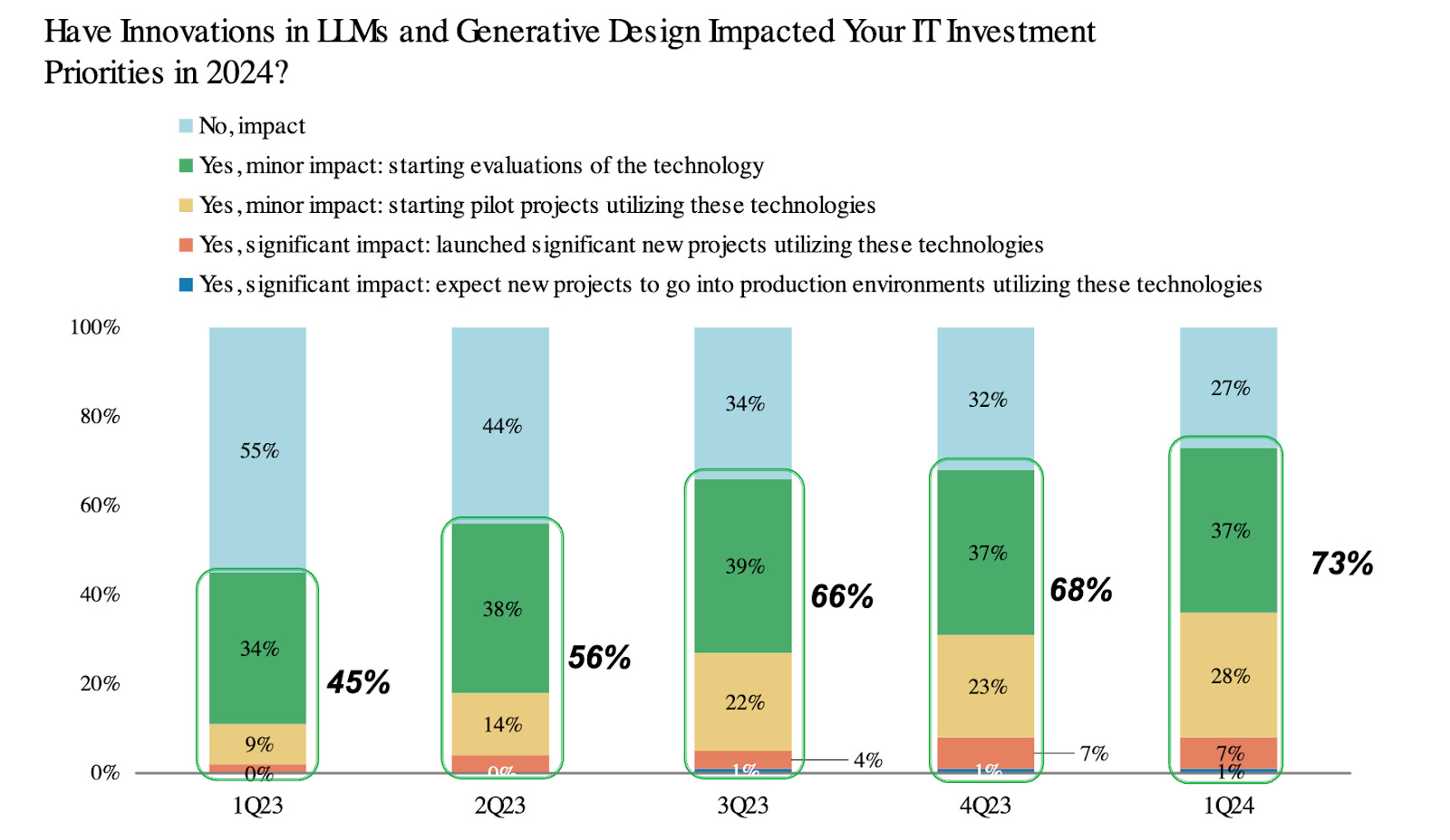
Model output accuracy and hallucinations are the two obstacles preventing enterprises from moving LLM use cases into production - this is why we are seeing a bifurcation of adoption cycles between internal and external use cases, with considerably lower hallucination tolerance for the latter.
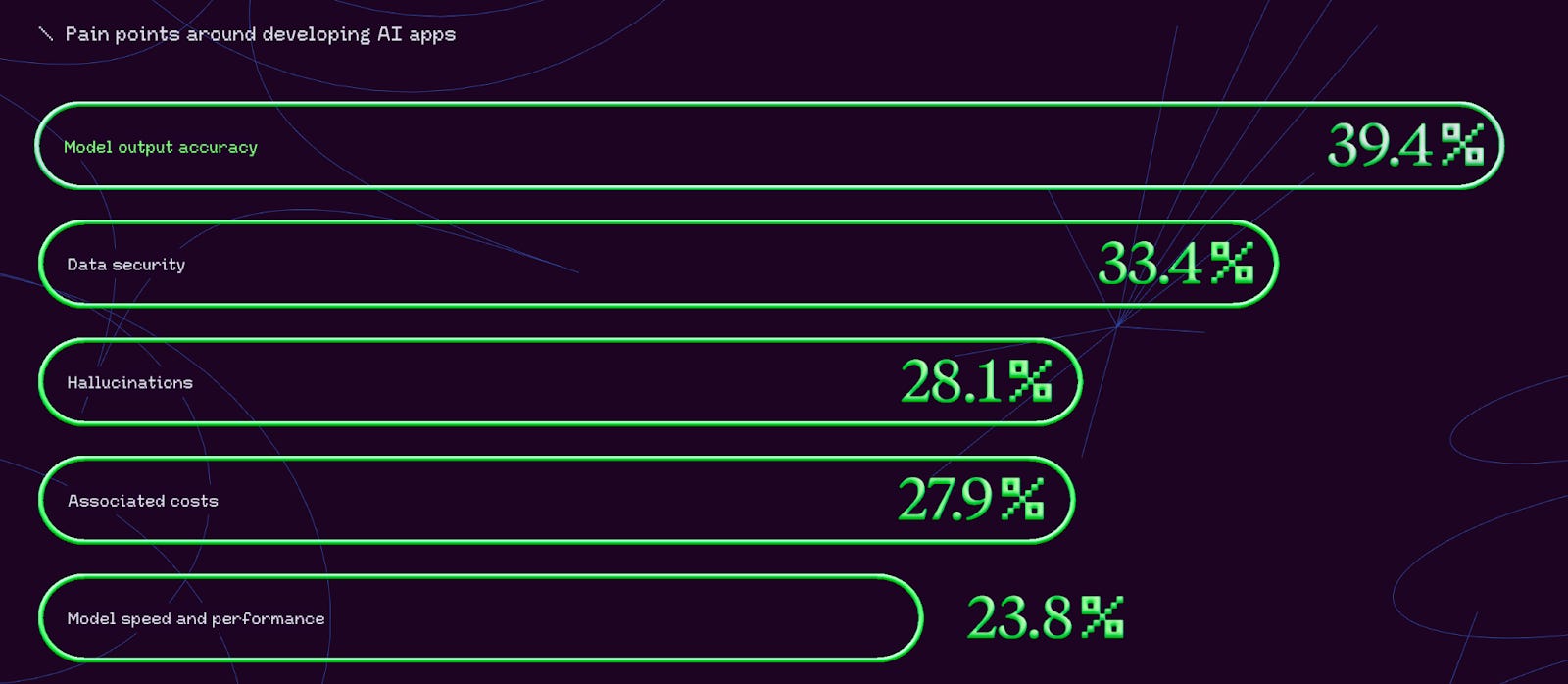
Enterprises are becoming more sophisticated on a range of deployment considerations like combining SLMs with LLMs, inference optimisation, model routing, and agentic design patterns (to name a few). Preceding all of these considerations though is the apparatus needed to get simple applications off the ground, namely retrieval systems around off-the-shelf/fine-tuned models.
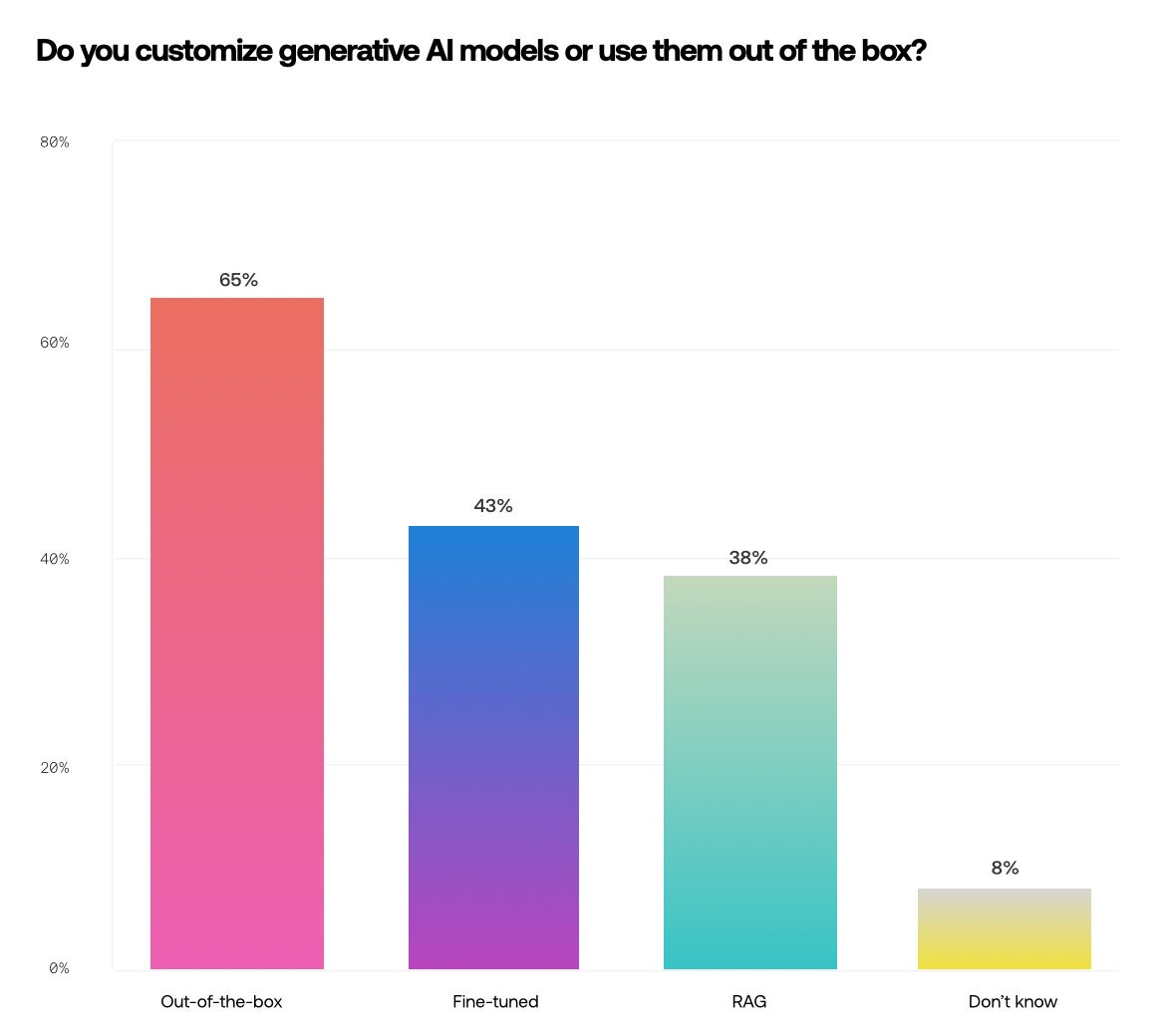

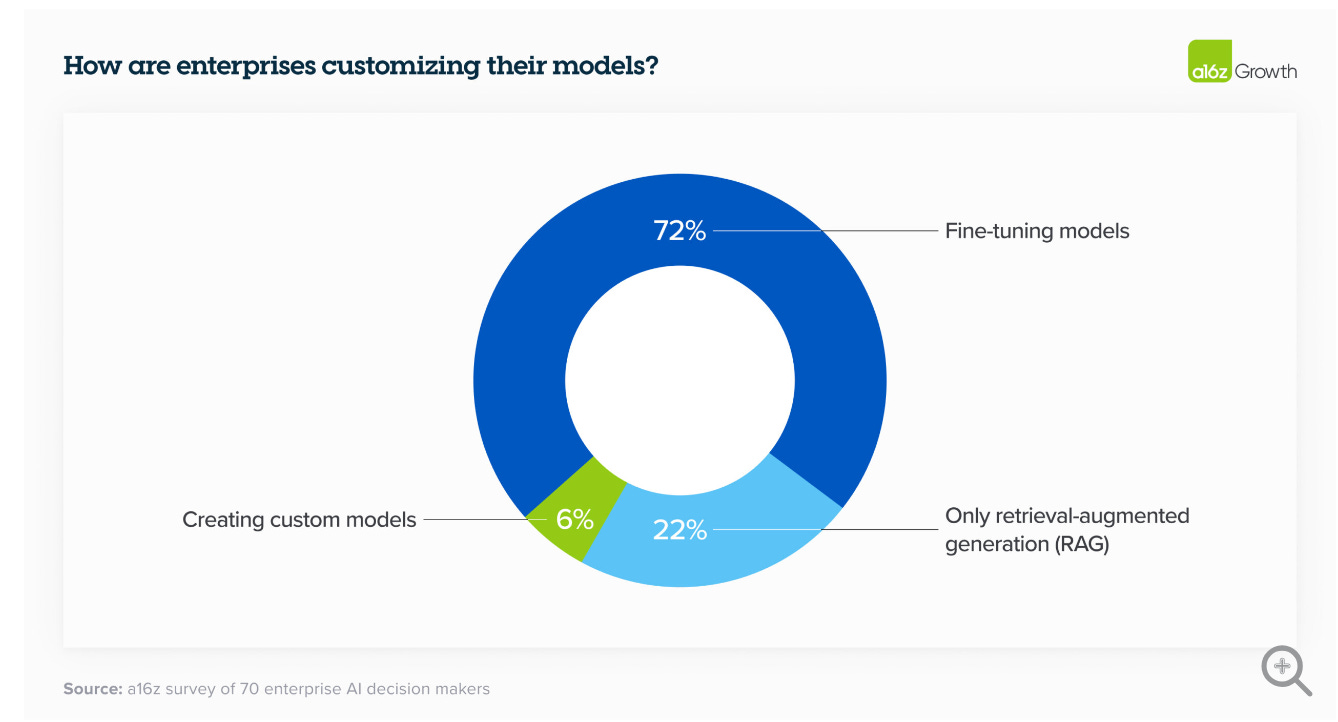
Fine-tuning and RAG are the two principal ways companies are customizing LLMs, though these are not mutually exclusive.
Indeed, there is increasing consensus that out-of-the box LLMs need to be augmented - Matei Zaharia, Databricks CTO, described compound systems as the following:
‘As more developers begin to build using LLMs, however, we believe that this focus is rapidly changing: state-of-the-art AI results are increasingly obtained by compound systems with multiple components, not just monolithic models.’
In enterprises, our colleagues at Databricks found that 60% of LLM applications use some form of retrieval-augmented generation (RAG), and 30% use multi-step chains.’
Anyscale produced a helpful taxonomy that elucidates the various use cases that RAG and fine-tuning are appropriate for:

Efficient fine-tuning with techniques like LoRA can cost-effectively imbue a base model with domain-specific knowledge, enhancing performance for highly verticalised tasks where the proprietary data was likely underrepresented in pre-training. RAG is still likely to be the better substitute for most enterprises from a purely economic lens, however:
An enterprise’s knowledge base is dynamic and constantly updating; repetitive fine-tuning runs can become prohibitively expensive, whilst retrieval data sources can be cheaply updated, supporting more real-time factuality in critical use cases
Context windows and recall are unlikely to asymptote soon, but retrieval of relevant context will always be cheaper than saturating context windows
Each step of the RAG process (pre-processing, chunking strategy, post-processing, generation) can be optimised for performance gains
RAG can be combined with citations to provide an audit trail and clear traceability of answers to sources, increasing trust in model outputs
As a public company, every basis point of margin deceleration is heavily scrutinised by analysts. RAG will be key to enterprises deploying LLMs at scale whilst also keeping costs in check.
There will be a spectrum of production RAG stacks from simple to complex:
Complex RAG systems, in contrast, are designed for intricate queries. They employ multi-hop retrieval, extracting and combining information from multiple sources. This method is essential for answering complex questions where the answer requires linking diverse pieces of information which are found in multiple documents.
One of the components of the RAG stack that’s received scant attention relative to vector DBs, embeddings models and data extraction providers is knowledge graphs.
Knowledge graphs help realize the full potential of RAG, and by extension Generative AI, by enhancing baseline RAG with additional context that can be specific to a company or domain. When you consider the proportion of white-collar tasks that entail information retrieval, incremental improvements in RAG performance generate significant economic value.
The combination of knowledge graphs and RAG with GraphRAG is becoming transformative for AI. Knowledge graphs organize data into interconnected entities and relationships, creating a framework that ensures that the responses generated by RAG are accurate and contextually relevant. We’re super excited by the traction we’re seeing from so many of our GenAI customers, by partners like Microsoft and Google, analysts like Gartner, and the broader community of builders. And it’s only just beginning.
Anurag Tandon, VP, Product Management, Neo4j
We can look to one of the leading enterprise software companies’ recent Analyst Day to see why they matter.
Enterprise AI with Knowledge Graphs
ServiceNow, at c. $10b in ARR, is an enterprise software juggernaut - and they’re all in on AI. The workflow automation platform saw its AI SKU achieve its fastest ever adoption of any product release and management recently cited some examples of productivity gains delivered to enterprises during their Analyst Day:
30% mean time to resolution improvement
>80% self-service deflection improvement
+25% developer velocity
ServiceNow highlighted the three pieces to their AI fabric, with one of those being Knowledge Graphs.

For ServiceNow, Knowledge Graphs are primarily used to make LLMs deterministic with respect to the data held on employees, namely the relationships with other employees, services, and integrations. Baseline RAG workloads are significantly enhanced in terms of relevant, accurate context retrieval when using knowledge graphs. For ServiceNow’s enterprise customers, employing knowledge graphs to structure their data and optimise retrieval moves the needle on reliability to make use cases production-grade.

Here is another enterprise, Deutsche Telekom.

Deutsche Telekom has also recently talked about how they are early in using knowledge graphs to increase the accuracy of their coding assistant co-pilot. Here, they use both RAG and Knowledge Graphs to help understand how to deliver personalised coding support to individual developers and teams.
“Knowledge graphs will be crucial to unlock vertical AI agentic workflows, enabling AI to surface nuanced context from enterprises’ proprietary internal knowledge bases. This firm-specific context not found in semantic similarity, such as patterns in similar deals and client entity relationships, is essential judgment professionals rely on to execute critical decisions in their deal workflow. Enterprises in finance and legal should especially pay attention to knowledge graphs as an opportunity to drive more value from generative AI solutions.
Kwesi Acquay, Redpoint
The emerging advanced RAG stack
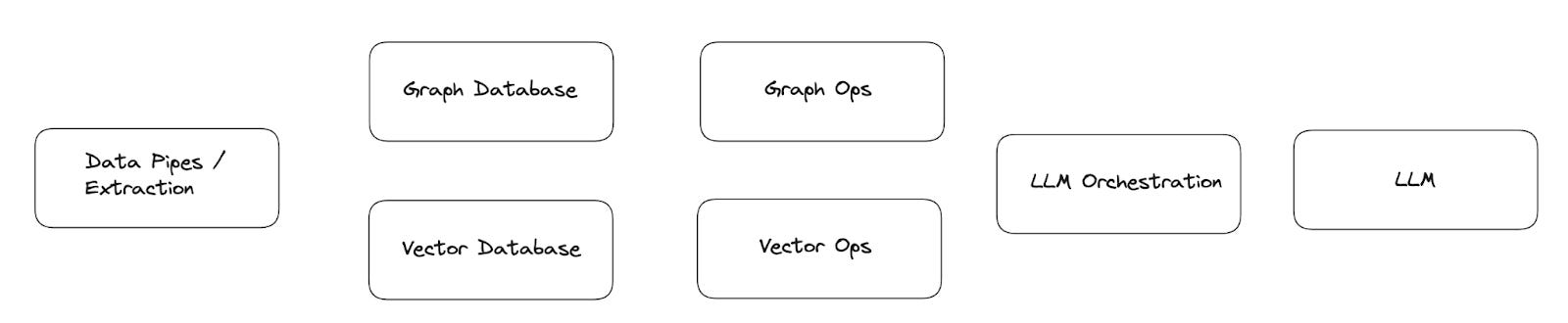
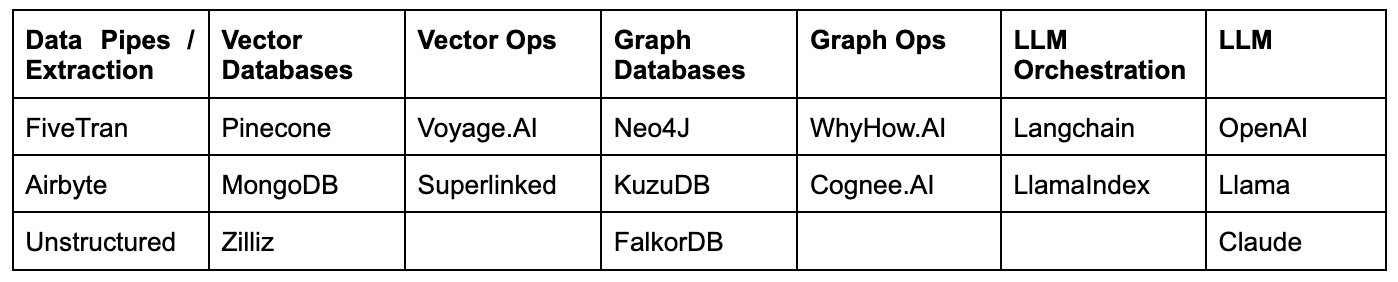
The emerging RAG stack comprises of a few components:
Data Pipes/Extraction:
Unstructured data needs to be piped in from a particular location, and data extraction remains a key bottleneck in the space (This can include simple text extraction from Powerpoint / PDF documents, etc.)
Vector Databases
Vector databases are used to store the mathematical embeddings or vectors that represent the underlying text.
Vector Ops
Vector Ops refers to the streamlining of processes that span the gamut of vector creation, vector optimization, vector analytics, etc.
Graph Databases
Graph databases are used to store the graph structures that represent the semantic connections and relationships between the underlying text
Graph Ops:
Similar to Vector Ops, Graph Ops refers to the streamlining of processes that span the gamut of graph creation, graph orchestration, graph optimisation, agentic-graph analytics, etc. Nuanced differences between Vector Ops and Graph Ops include a greater need for workflow tools in Graph Ops given the many ways that information can be represented hierarchically and within networks. The same information can be represented in different ways, depending on the use-case.
Graph/Vector Databases:
Graphs can be used both for data storage as well as a structured data orchestration layer. This means that graphs can be used to store knowledge to be retrieved in a specific way, or store logic about how data sitting somewhere else (like in a vector database) should be retrieved in a specific way. In this way, they sit either in replacement of, or in parallel to, a vector database within the broader RAG system
LLM Orchestration:
Being able to manipulate information with a multi-agent system can get tricky, and abstraction layers for LLM orchestration have emerged to address this need
LLM
These are the underlying foundational models that RAG systems sit on top of, to return the appropriate, relevant information for LLMs to formulate answers on top of.
Knowledge Graphs as an unlock
Knowledge graphs are fundamentally a collection of nodes and relationships. Nodes represent individual data points, while relationships define the connections between them. Each node can possess properties, which provide additional context or attributes about the node. This approach offers a flexible and intuitive way to model complex relationships and dependencies within data. It has often been described that knowledge graphs are a close way to mimic how the human brain thinks.
Graph databases/knowledge graphs have been around for a while, but its historical application has been niche. Historically, the application of knowledge graphs were largely used akin to data dictionaries - a means to enforce semantic structure across different terms across different data silos, and to unify data-sets to unveil hidden relationships. For example, being able to link “user_id” in one database and “USER-name” in another database. This use-case was a painful manual process that only large companies would even bother with, and typically had to be done manually by a domain expert. The main value proposition then was for big data analytics.
However, LLM RAG systems have emerged to be a consumer of knowledge graphs for a completely different value proposition. The ability to make explicit connections between words means that you can enforce specific meanings between words. For example, being able to ensure that the LLM understands that “USER -> Owns_A -> Golden_Retriever -> Has_A_Disease”. By looking at structured graphs for their knowledge base, this helps enterprises reduce hallucinations, inject context, whilst also acting as memory, a personalisation mechanic, and a structured supplement to probabilistic LLMs.
With this use-case, the interesting piece is that while knowledge graphs can help make RAG systems enterprise-ready, LLMs can also help automate knowledge graph creation. So while the interest and need for knowledge graphs has increased, LLMs are also available to be structured in workflows to automate different types of knowledge graph creation, increasing the applicability and accessibility of graphs.
Knowledge Graphs fit within RAG in two ways:
As a data store to retrieve information from
As a data store of the semantic structure to retrieve vector chunks from
If they are a data store, they can be used in parallel with, or in replacement of, a vector database. If they are a data store of the semantic structure to retrieve vector chunks from, they would be in parallel to a vector database.
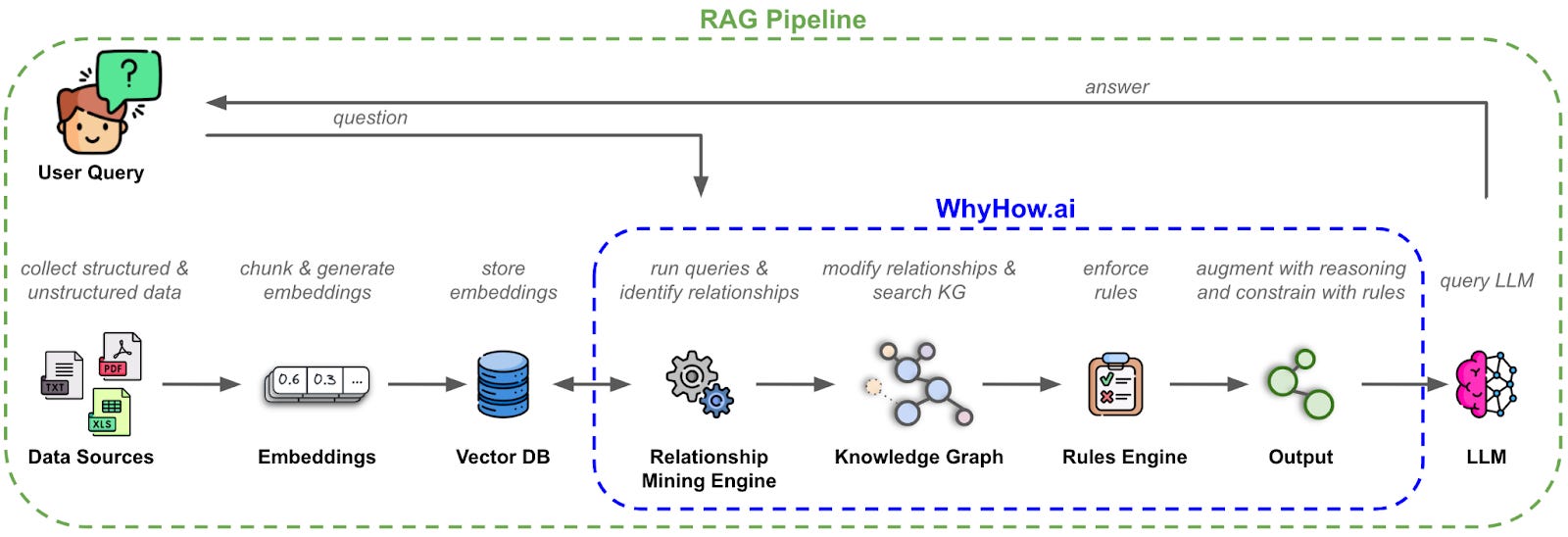
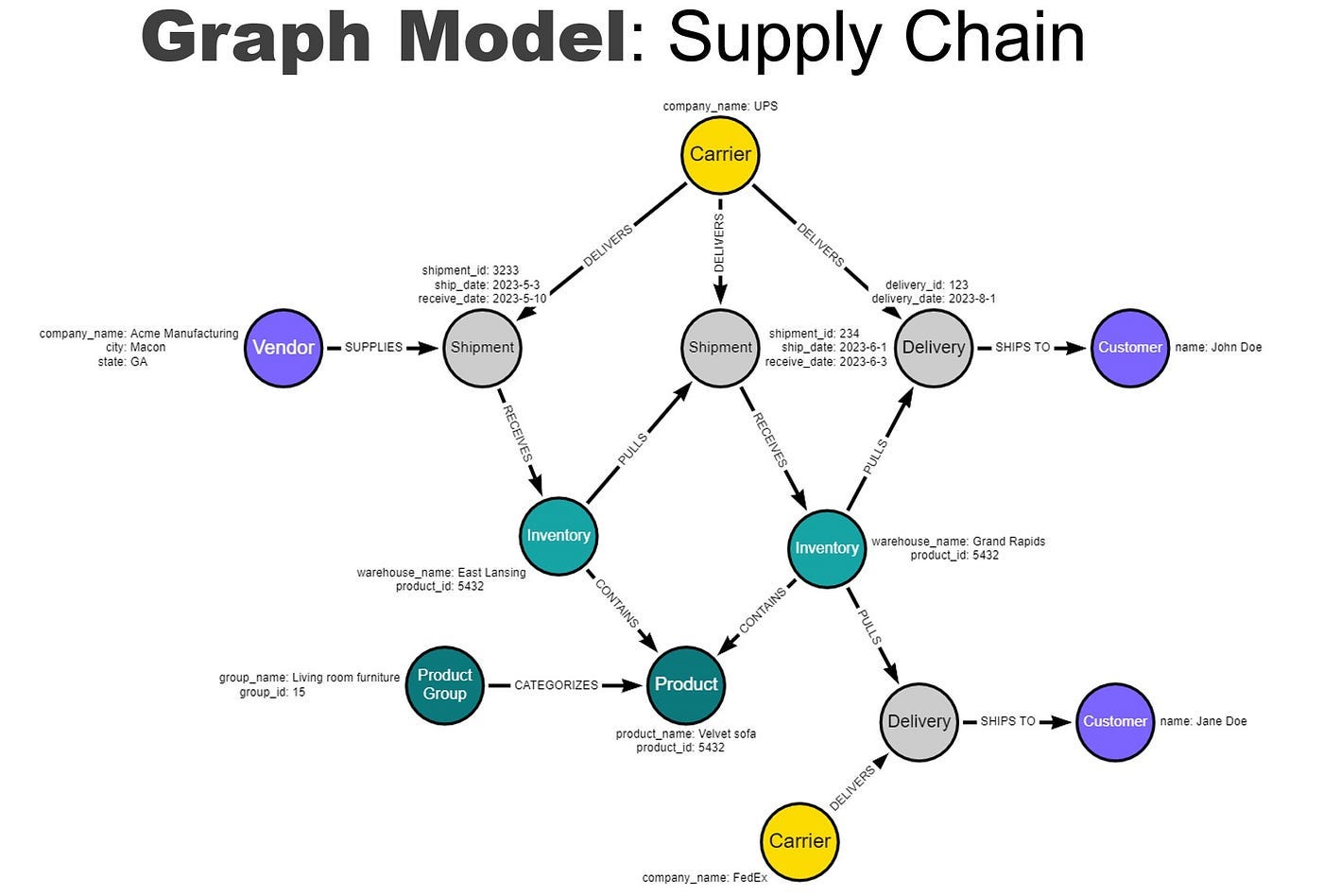
As a data store, what goes into the knowledge graph requires a nuanced understanding of what data is important, what type of knowledge representation is best (i.e. do I store a document structure, or a concept-based relationship map, etc), how each graph interacts with different agents in a RAG system, etc.
This requires workflow tooling and discrete data pipes to help manage the orchestration of the different graphs containing different data types and levels of data abstraction. Just like you don’t use a single prompt to try to capture all the ways a workflow can be described but rather break it into many discrete prompt and agents, a single graph or table to store all data is unwieldy, hard to create, and hard to maintain or orchestrate, and a series of small graphs is preferable for information retrieval workflows.
Scenarios where Knowledge Graphs are more or less relevant
There are a few ways to think about how and when Knowledge Graphs should be used within a RAG system.
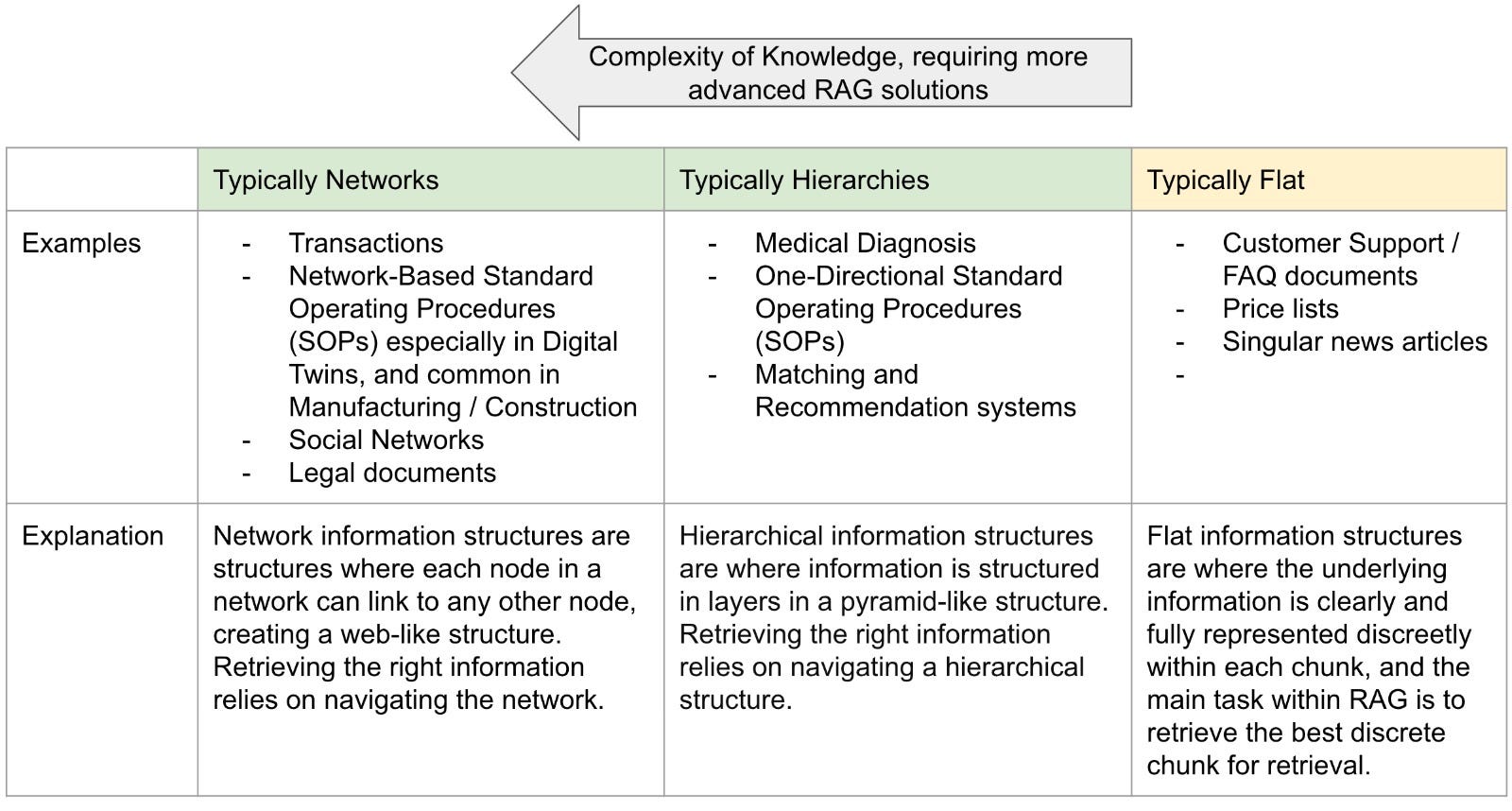
First, let’s examine the practical list of scenarios where Knowledge Graphs can be used versus not used. The main consideration here is in the complexity of the underlying data, and whether there are hierarchical or network structures that are involved in the retrieval process.
Scenarios where Knowledge Graphs play a role:
Conceptual Aggregation: Two different documents or data sources that require combination or talking with each other
An example of this is when you are trying to combine information from multiple documents and data sources. One example of how this is useful is when creating a RAG system for a VC fund. The VC fund has a contact list of people, industries they work in, and funds they are connected to. The people, industries and funds would ideally be connected to the broader set of context and data that exists, such as unstructured text like news articles.
This can also be seen as a form of multi-hop reasoning as it allows you to automatically combine information from multiple sources if they cover the same concept or context.
Conceptual Alignment: Two different domains automatically communicate with each other
Within an enterprise workflow, bringing new information into an existing knowledge base means that you need to align how specific new information needs to interact with specific parts of existing information
An example of this is linking clinical care practices to patient records in a healthcare context. For example, the external best practices for clinical care are being updated with new research and clinical trials. This information can be directly transmitted to patient records and their specific patient histories. The result is a direct communication of the latest safe, tested clinical care practices to the specific patients that are most likely to benefit from the new research.
Another example of this would be in the agricultural industry, where many different specific domains contribute to the decisions and the outcomes. For example, specific weather data combined with specific soil data, and communicated together, are necessary to understand performance and yield. This weather and soil data are different domains, with different updating frequencies, and different granularities, with different vendors, and all of this needs to be understood together for the best result. The outcome of aligning this information is a more comprehensive understanding of the current and predicted performance of the broader agricultural system, facilitating more accurate yield and costing information, allowing you to leverage the power of unstructured expert recommendations and LLM reasoning capabilities. A case study with soybean pest recommendations can be seen here.
Comprehensive Digital Twins are the ultimate example of this, as digital twins need to combine many different domains together in a representative system. For example, in a construction use case, understanding how the plumbing system and the electrical system may interact within the construction process requires alignment of specific concepts (i.e. building timelines, physical spaces being operated on, etc).
Hierarchical Retrieval: Deterministic retrieval through hierarchical steps / categorisation
An example of this is in the veterinarian healthcare example below that show how hierarchical retrieval of symptoms and diseases by first traversing dog breeds allow for more deterministic retrieval
This is also common in Standard Operating Procedures where there is a hierarchy of steps that must be followed before the ultimate correct answer should be retrieved. This hierarchy in complex scenarios may also look like a network where specific steps may return you back to an earlier stage in the process.
Hierarchical Recommendation: Improved recommendation systems through hierarchical categories
Personalisation / Memory:
Memory and personalisation are two sides of the same coin, since personalisation is simply an opinionated memory that is to be returned and considered in specific scenarios. This opinionated memory can be predefined through the schema of the graph.
Let’s say that you want to personalise the interaction between your personal finance AI system and your user. You know that you want to personalise it by making sure the LLM keeps track of the hobbies of the user whenever it is mentioned, so you can suggest activities related to the hobbies in the future. You can now set the schema (“hobbies”), describe what the schema should look like, and then extract all the hobbies that the user mentions they have, over time, across all conversations for future extraction, into a knowledge graph.
Scenarios where Knowledge Graphs do not play a role:
The number of errors in your system is low and the nature of the specific error is not serious, and can be solved by manual agentic systems to build the semantic connections by hand.
Consumer-facing chatbots where the tolerance of error is higher
Non-hierarchical, non-semantically similar answer sets/knowledge base (i.e. FAQ Q:A base)
Time-Series information
A more generalisable framework to think about where Knowledge Graphs are relevant can be in understanding if your underlying information should be represented as a Network, or as a Hierarchy, or Flat.
This assessment may not necessarily be done on the entirety of your data, but on the specific information that you are trying to perform RAG across. A single organisation may simultaneously have specific information that is flat, and specific information that is hierarchical.
Where there is a non-flat structure within the information itself that requires specific traversals, graph structures like knowledge graphs can help represent hierarchical or network structures that enable more specific structured retrieval of information.
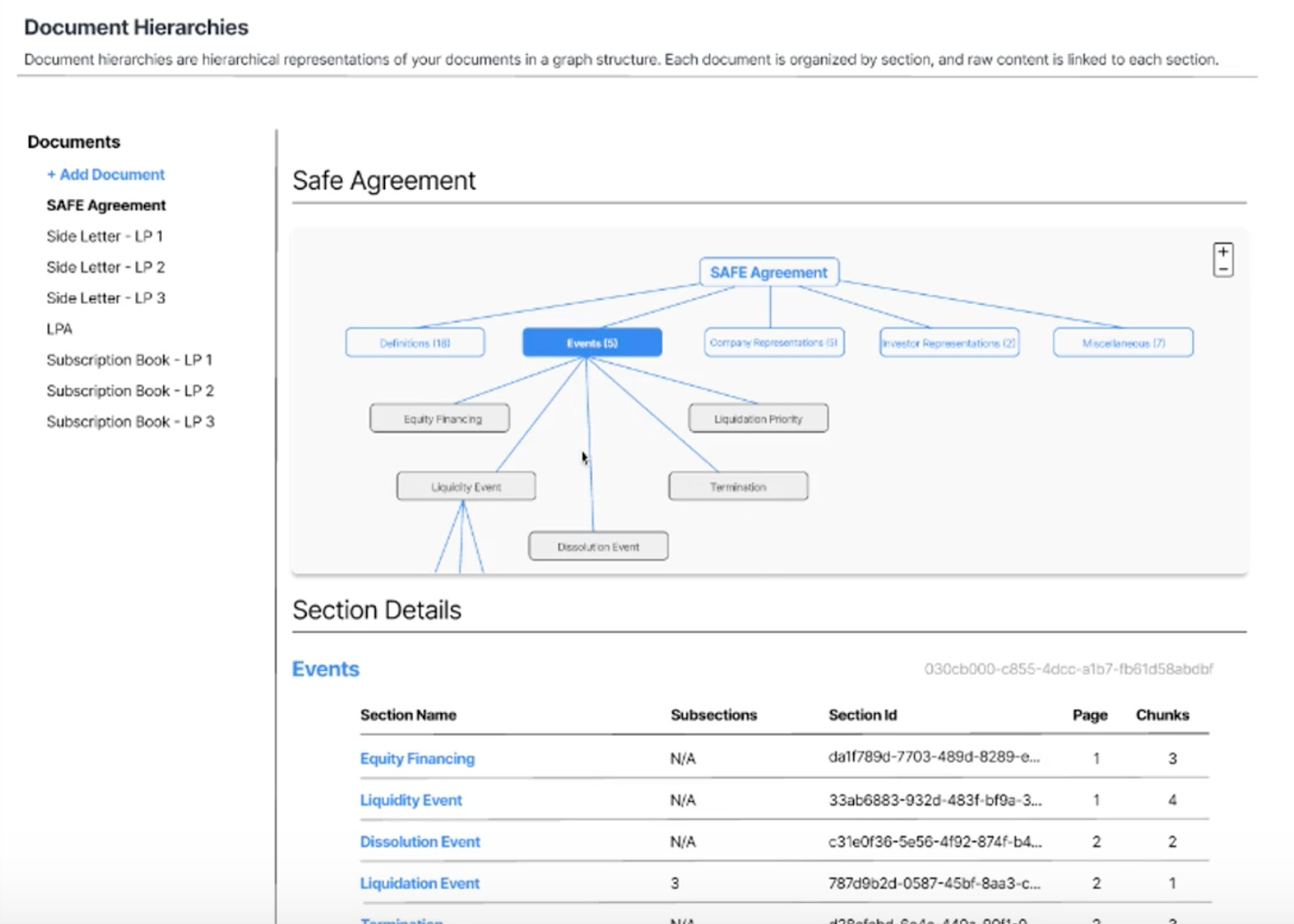
Hierarchical information structures can exist in a variety of ways that may not be apparent as ‘complex’. For example, customer support is traditionally not seen as a complex information system. One hypothetical problem in a retail customer support use case is to be able to ensure that the right opening hours are retrieved for the right store. However, limitations with semantic similarity mean that random opening hours are sometimes returned as the answer.
This WhyHow.ai design partner then wanted to represent all the information about stores within a shopping mall as a graph. This was so that when the LLM was seeking to retrieve relevant information, it would traverse the graph, first identifying the specific store mentioned in the question, and then retrieving the opening hours tied to that specific store. Since the information was in a graph, the opportunity to hallucinate and mix up different opening hours for a store was much lower since the retrieval process was much more structured.
A case study of how Knowledge Graphs can work in RAG
Another design partner is a veterinary healthcare startup that wants to compare diseases and symptoms across animal breeds. This design partner is building AI-enabled tooling for veterinary radiologists to help them quickly diagnose animal diseases and generate reports. They tried to supply animal history, expert opinion, as well as medical documentation (retrieved from a vector database) to an LLM to generate a report of a sick animal’s diagnosis, treatment options, and next steps. However, given that there are many different types of diseases and treatments that an animal can have depending on their breed, reliably retrieving accurate information on a per breed basis from a vector database was not working. Vector similarity searches were returning information about diseases that could apply to any animal. Therefore, many of the generated diagnoses and treatment information was incorrect.
This design partner is working with WhyHow.AI because they knew they needed a more structured approach to organising and retrieving their data that did not require them to go through another lengthy process of re-optimising their chunking, tagging, or sharding strategies.
This design partner wanted the following:
A well-structured graph that adhered to a specific ontology of animal breeds, their diseases, and their treatments
A way to continuously update the graph with new information about new breeds of animals without having to manually rebuild graphs over and over again
Impact:
Since each animal has their own graph of possible symptoms and diseases, the RAG system can query graphs on an animal by animal basis and be confident that they will only get back information about that animal, eliminating the risk of irrelevant information being introduced.
“Current LLM approaches have a hidden ceiling for accuracy that was not getting addressed. Knowledge graph structures though WhyHow.AI infrastructure provides a unique approach, allowing us to use AI in radiology reporting that was not possible before. This has shown how our data can be used more efficiently for reliable workflows, to be more specific, and detailed at a faster pace.”
Design partner
Knowledge Graphs as a long term strategic moat for domain-specific corporates
Companies may increasingly look to use knowledge graphs as they look to understand how they can create a moat in the new AI age. The key moat that most companies have is specialist knowledge and data within a specific industry. The main question is how to turn that existing data, most of which is unstructured, into a specific and tangible advantage. The two main ways that people are approaching this question is in either training a domain-specific model, or to build an internal knowledge base that makes it easier to further exploit, manipulate, or interact with this data, through some type of structured knowledge base - including with knowledge graphs. The story of BloombergGPT represents some of the potential pitfalls with training a model, and companies are increasingly seeing knowledge graphs as their long-term moat, since it can act as a scalable structured representation of their domain expertise, that can be used as a foundational building block for both RAG and even using the completed graphs to fine-tune a specific model in the future.
This is to say, in an age where underlying technologies from third parties are developing at breakneck speeds, focusing on cleaning your domain-specific proprietary data to be plugged into these systems, represents a foundational building block that will always remain a moat.
It is not clear that we need to spend millions of dollars training a model that may or may not overlap with some of the foundational models. But representing our knowledge in a structured way is something that can give us both short and long-term advantages.
Design Partner
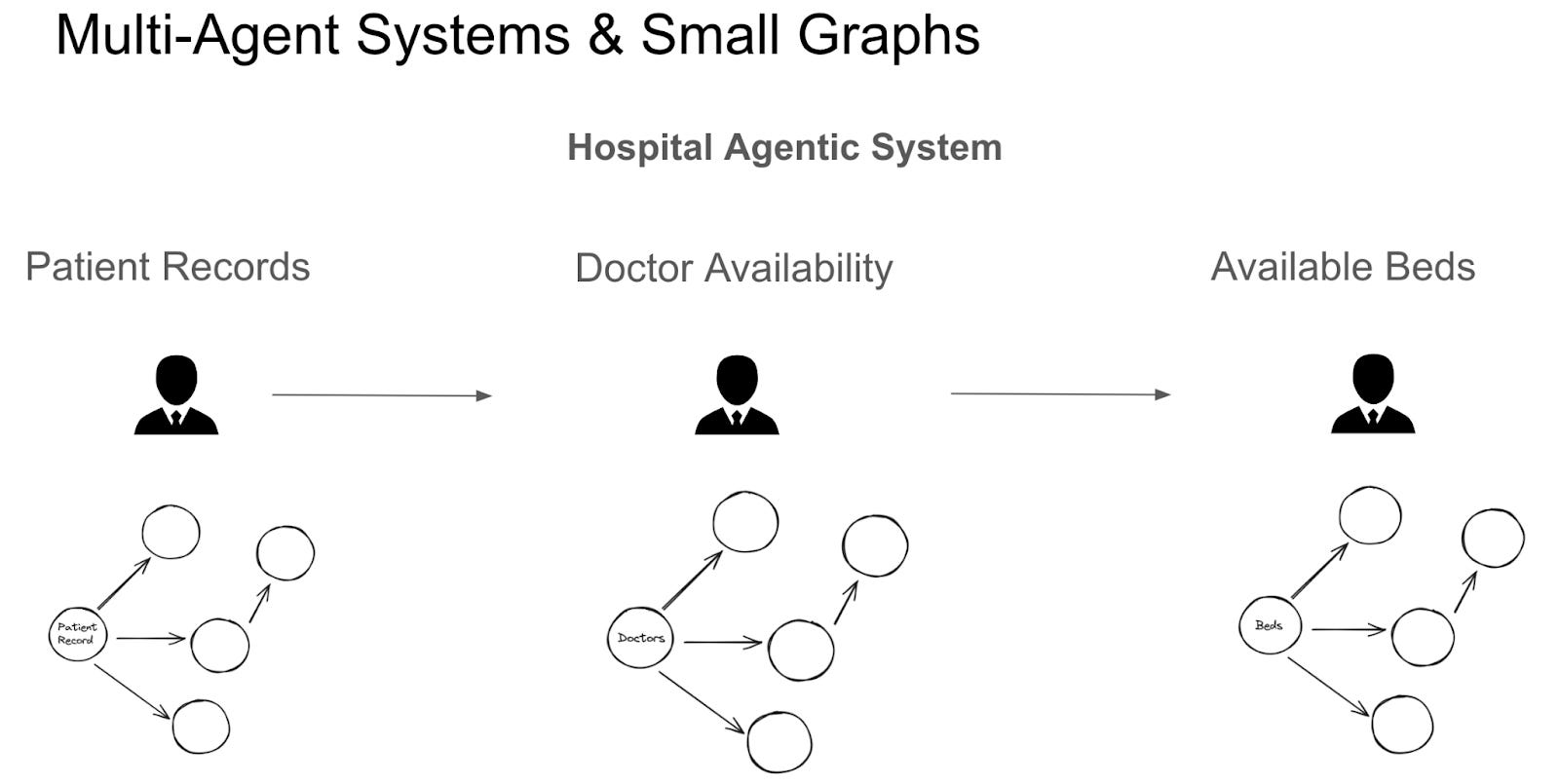
The Future: Small Graphs & Multi-Agent systems
A big difference in how graphs are being adapted to RAG pertain specifically to small graphs. Instead of creating a large representation of knowledge of all data, LLMs and workflow tooling can help create very specific knowledge representation of the information that matters. This is especially useful in the context of multi-agent RAG systems that will emerge as information retrieval systems get more complex.
With smaller sub-graphs that are independently managed, and tied to a single agent each, we then have the ability to allow for the manipulation of knowledge on a per concept, or per sub-graph level.
The image below shows a multi-agent system, with each agent representing a specific step in the information processing stages for a Hospital Onboarding process. By breaking down the process agentically, and having small scoped in graphs about patient records, doctor type & availability, and available beds, each agent does not need to perform a complicated data extraction process from a large all encompassing ‘hospital graph’. Since the graph is scoped in, the surface area for hallucinations is smaller, and the task of dynamic retrieval of relevant information is easier. Just as we use multi-agent systems over single-agent systems for complex processes, we will increasingly use multi-graph systems over single-graph systems for complex information retrieval processes.
Concluding remarks
As RAG becomes a core technique for enterprise adoption of Generative AI, the RAG stack and knowledge graphs in particular will become integral to imposing degrees of determinism on probabilistic large models. Furthermore, knowledge graphs can serve as critical infrastructure to enable future generative AI innovation, such as AI multi-agent systems.
Considering the trillions of dollars of labour costs that are addressable for AI and the proportion that entail information retrieval, the RAG stack will be foundational to putting both internal and external use cases into production with reliability and enhanced performance.
Charts of the week
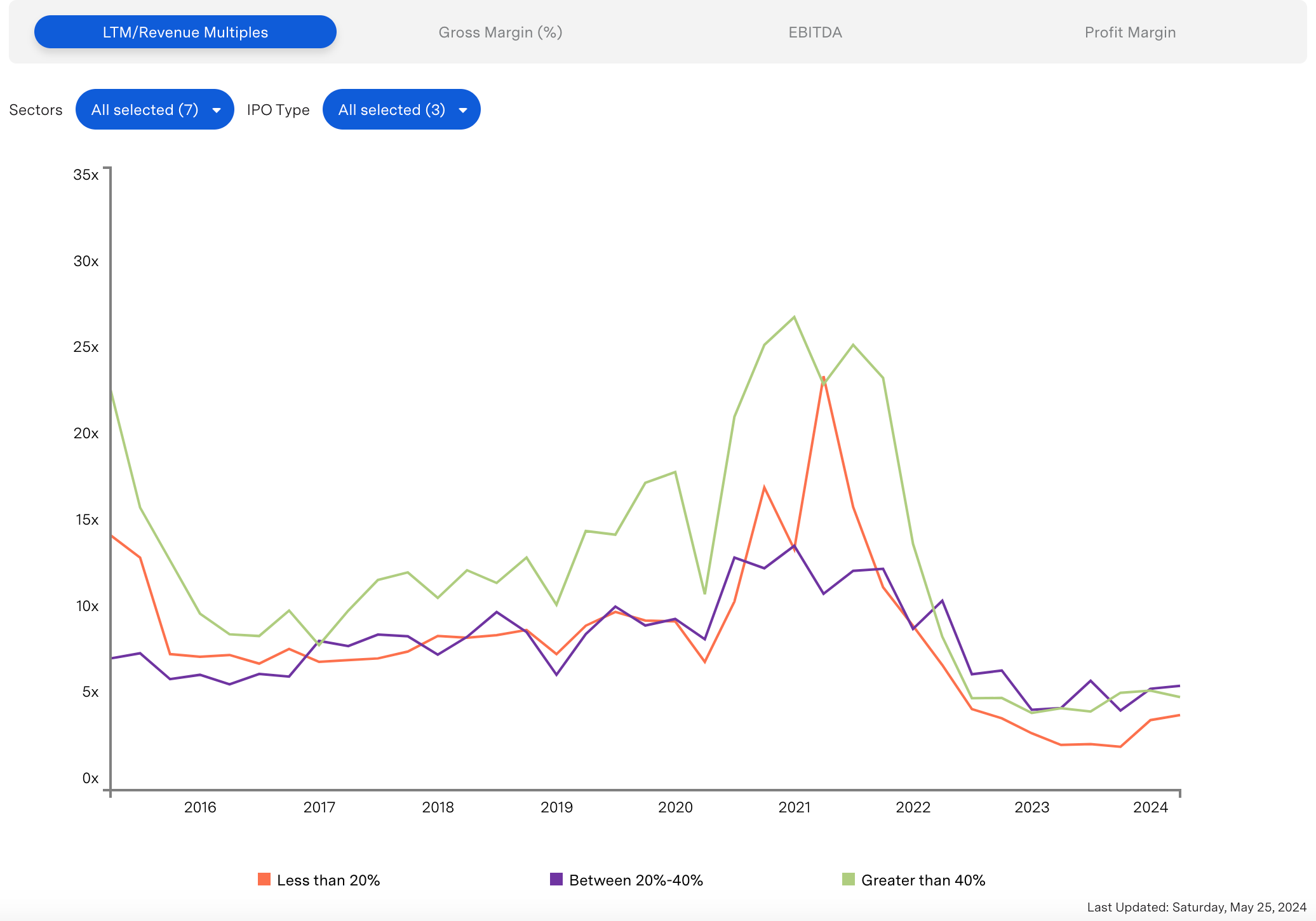
Fintech multiples continue to trade below historical averages
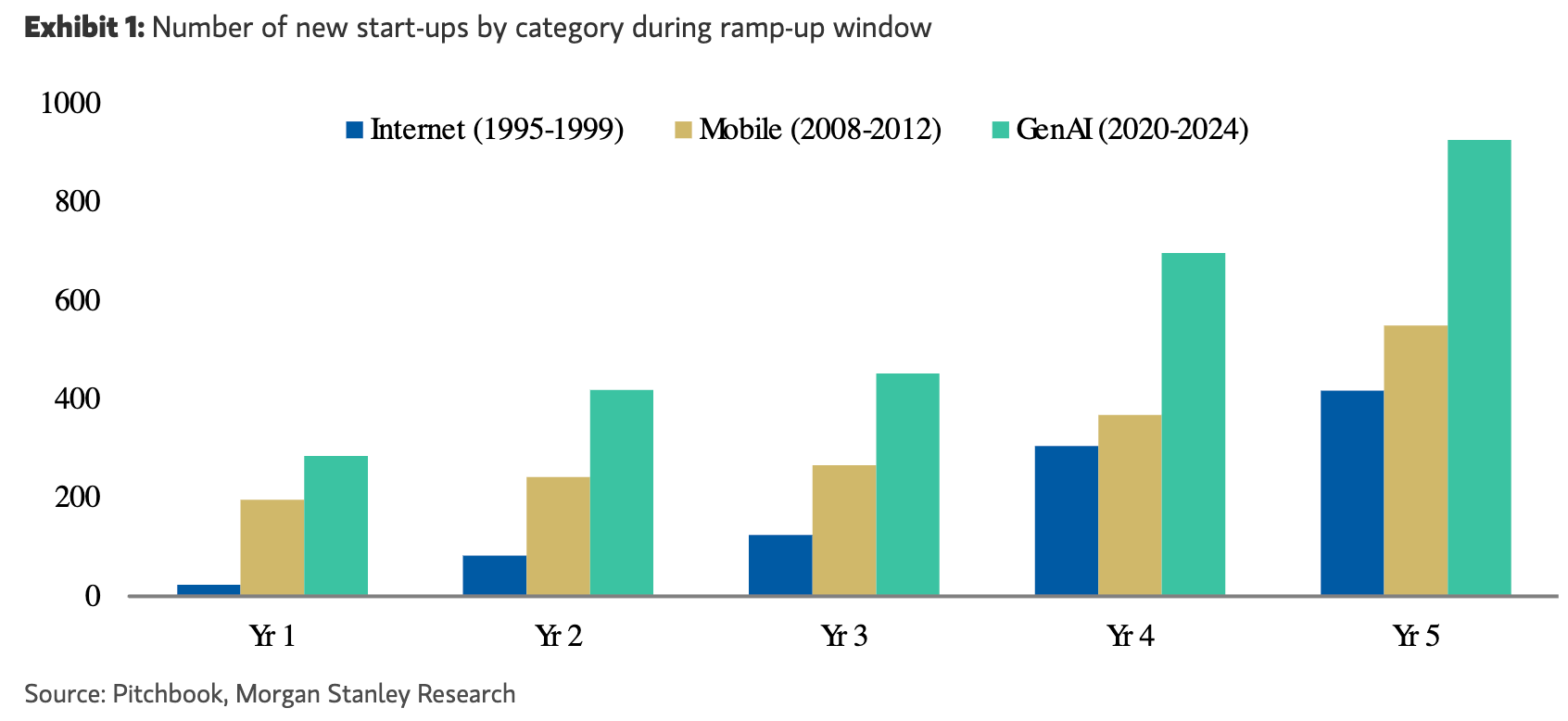
The rate of AI company creation is far surpassing previous technology waves
Curated Content
The future of foundation models is closed-source by
Marcus Ryu on the Logan Bartlett Show
Mapping the Mind of a Large Language Model by Anthropic
Do websites go away with AI agents? by Theory Ventures
Quote of the week
‘For ~4 years all we've had to really control LLMs is temperature/top_p and logit bias. We recently got `seed` and constrained structured output, with `interactive=false` on the way.
But now Claude Sonnet can let people clamp up/down 34 million features ranging from famous people and noun categories to abstract concepts like its ability to keep a secret, code errors (!) and its representation of self. This is "representation engineering writ large", and probably easy to retrain the SAEs for any set of features you care about.’
Thank you for reading. If you liked it, share it with your friends, colleagues, and anyone that wants to get smarter on startup strategy. Subscribe below and find me on LinkedIn or Twitter.
 | A guest post by
|