

Reducing data deficits as an AI startup
Reducing data deficits as an AI startup
Wrangling data from gatekeepers predates LLMs

Hey friends! I’m Akash 👋
Welcome to Missives, where I write about software, fintech and go-to-market strategy. You can always reach me at akash@earlybird.com.
Thank you for reading! If you enjoy these Missives, please share them with your friends and colleagues 🙏🏽. Wishing you a great week!
Current subscribers: 2,985, +40 since last week

Most systems of record and application software vendors sitting on high quality data had a ‘Code Red’ moment after the initial release of ChatGPT.
Front and back-office application software vendors swiftly released LLM-enabled products that leverage unique data sets collected across their suites of products.
Case in point: Intuit.
Goodarzi believes that an early gamble on A.I., along with a massive trove of data, is a winning strategy to extend the company’s domination of tax and accounting software for individuals and small businesses. And he has quite literally bet his entire company on the idea that millions of people will trust an A.I. service to recommend specific, personalized business decisions.
Speaking more recently, he said that when it came to a new strategy, “the decision I made was, we’re going to bet the company on data and A.I.” Intuit already had data from its 57 million customers, which gave it a significant advantage when it came to financially-focused A.I.
“Everybody wants to talk about how great their data is,” says Jackson Ader, a MoffettNathanson analyst who covers the company. “But Intuit’s dataset, on the consumer side or small business side—it’s second to none.”
The rate of releases presents substantive evidence in the discourse on value capture compared to the cloud shift.
‘Moving from on-premise to the Cloud required a complete rebuild. There is no smooth transition path from single-tenant databases and desktop UIs to scalable, multi-tenant databases and a UI that runs in the browser. It’s a complete overhaul of the software architecture, rebuilding it from the ground up.’ Christoph Janz
‘The LLM API form factor means quick integration, and incumbents’ wide distribution means they show the fastest wins. In the short term, AI seems to be a sustaining innovation, not a disruptive one.’ John Luttig
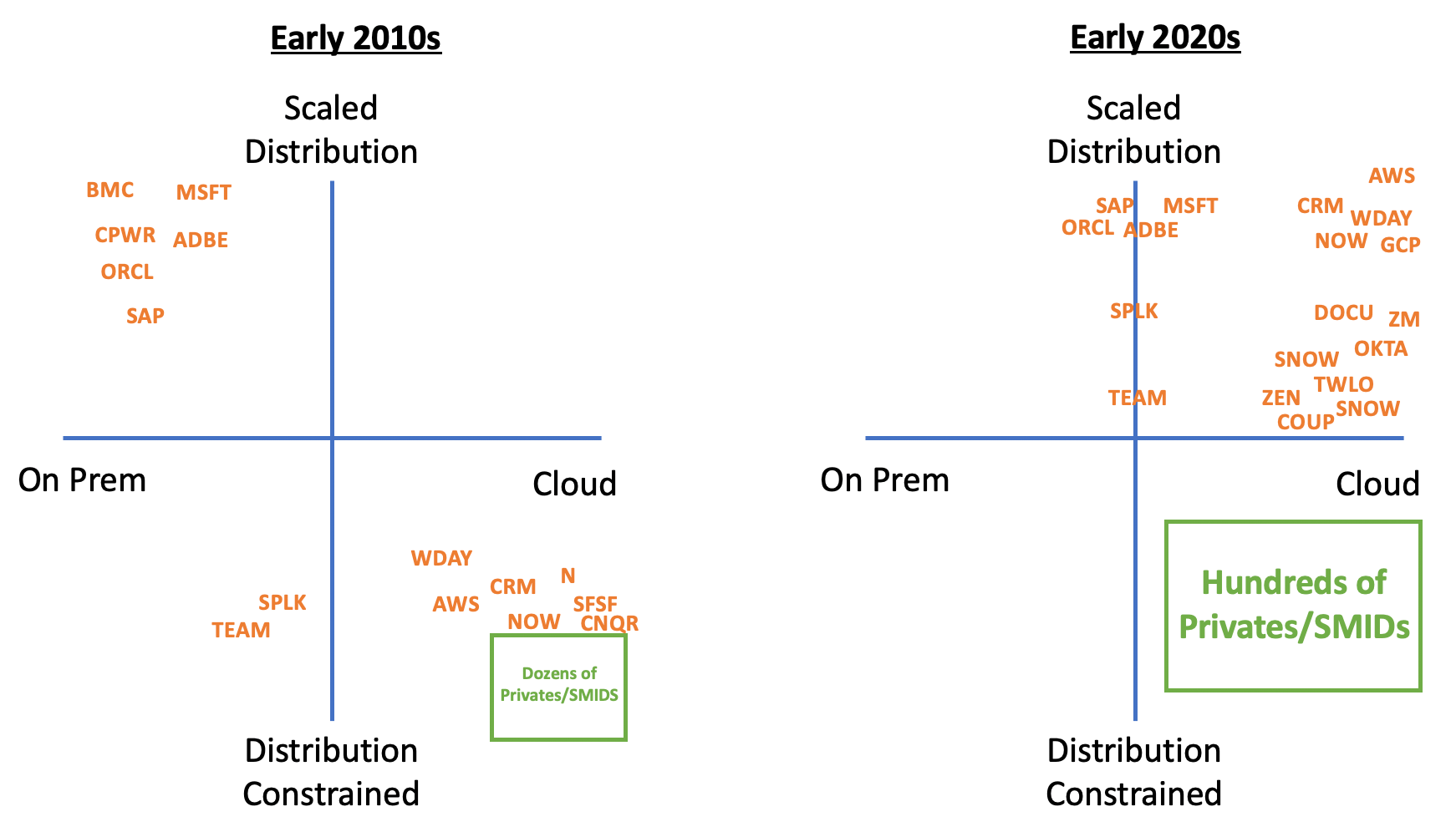
We’ve previously discussed how systems of action can tackle systems of record by navigating a path of least resistance towards product parity. Systems of action inherit the right to own interaction and intent data, for example, which can power products like ZoomInfo and prove far more valuable than the stale data in the CRM.
The headwind to this strategy is the capabilities that LLMs confer to systems of record.
‘Incumbents will be advantaged on their own data. For example, Salesforce is building a system of intelligence, Einstein, starting with their own system of record, CRM.’ Jerry Chen
The journey to product parity is always going to be fraught with interstitial reliance on the data guarded by the system of record. It’s paramount that de novo application builders explore the surface area of quality data sets they can secure.
Mark Roberge of Stage 2 Capital gave a presentation at SaaStr Annual that spoke to the data set deficits that startups are born with.

Startups in their infancy have always had to wrangle to access critical data sets that power their applications, well before LLMs came to the fore. Kenneth Lin, co-founder and CEO of Credit Karma, recently described the near-death experience of receiving a 30-day notice of termination to credit bureau data.
Here’s your notice. In 30 days, we’re turning the lights off in terms of the API—which is, obviously, the main thing that we needed from a product perspective. Over the course of a week, we went from the high, feeling like we built this product that made it, to a ticking time bomb. In 30 days, it’s going to explode, and you’re not going to have the data sources that you need to build the product.
Kenneth exhausted his network to eventually discover the person responsible for the decision and ended up convincing him over a meeting that Credit Karma’s early traction vindicated their right to continued access to the API:
I kind of reflect upon this idea that asking for forgiveness rather than permission really mattered. Building the product, getting traction, and being able to point to 10,000 users gained over the month that we’d launched—all for free—mattered. That’s what really got him excited, that maybe there is something there. Had we not gotten that far, had we not been able to demonstrate that traction, I don’t think this thing would have ever gotten off the ground.
Kenneth’s approach and perseverance is instructive; the early traction evidenced the use case for the data and the possible new revenue stream this presented for the data vendor.

For a startup to thrive around incumbents like Oracle and SAP, you need to combine their data with other data sources (public or private) to create value for your customer. Jerry Chen
Access to data stored in systems of record is a prerequisite, as we’ve discussed before.
After that, application software vendors can build on the data that’s most readily available: data flowing through their product suite or data that’s easily crawled.
Ramp built their Intelligence product on top of the data flowing through their product suite to drive cost savings and efficiencies for their customers, which ultimately increases the total ‘spend under management’. Gong is similarly leveraging call transcripts to power a suite of models for various sales workflows.
Most verticalised copilots/assistants start their data accumulation journey by crawling public data such as legal literature, product catalogues, or job listings.
The next step is the least well defined in the LLM age: accessing data through partnerships with data vendors. The exact nature of commercial agreements and any potential exclusivity with data vendors is still more art than science, with experimentation around different models (e.g. revenue share, commissions). For example, Nvidia has struck partnerships with Adobe, Getty Images and Shutterstock to access scarce data for custom models such as a text-to-3D foundation model, with each vendor giving kickbacks to the suppliers of data (artists, creators, etc).
Exactly where the demand and supply curves intersect for certain types of data will depend on the value of that data to an application builder’s ability to deliver a measurable delta in performance versus competition. Here, too, we’re still figuring out what’s the ‘Chinchilla optimal’ equivalent for domain and workflow-specific models and the size of data set required to reap measurable gains in performance over competitors.
Lastly, startups will need to invest in business development efforts focusing on data partnerships. ZoomInfo is the canonical example of best-in-class data business development. As CEO Henry Shuck described it:
We buy data.
We gather data through public sources.
We also have two contributory data models. One is we have a freemium model where people can get limited, free access to ZoomInfo in exchange for their email contacts. And so if you ever Googled somebody and you see ZoomInfo come up as one of the top results, if you want free access to ZoomInfo, you could your email contacts for that free access.
Although c. 35-40% of ZoomInfo’s data come from its contributory model, much of the value lies in its curation of data for third party sources and the margin ZoomInfo has built on top.
Reading List
B-Side: Case studies and celebrity impact on retention and pricing
Venture Capitalists Will Overpay For Seed Rounds But For Reasons You Likely Haven’t Considered
Quotes of the week
‘The technology ecosystem is about breathing life into figments of imagination and betting on the outside chance they become fixtures of how we live.’ Rebecca Kaden
‘You learn to accept rejection. You don’t take the world’s indifference personally. You begin to understand the meaning of ‘process over outcome’, that engaging in the act of creation is a privilege already. You abandon expectations and come to terms with your place in the universe.’ Frederik Gieschen
Thank you for reading. If you liked it, share it with your friends, colleagues, and anyone that wants to get smarter on SaaS, Fintech and GTM. Subscribe below and find me on LinkedIn or Twitter.