



Test-Time Search: A Path To AGI
Stacking Scaling Laws And Reward Engineering

Hey friends, I’m Akash!
Software Synthesis analyses the intersection of AI, software and GTM strategy. Join thousands of founders, operators and investors from leading companies for weekly insights.
You can always reach me at akash@earlybird.com to exchange notes!
Shortly after Ilya Sutskever declared the end of the pre-training paradigm at NeurIPS, OpenAI’s o3 model delivered a breakthrough in a well known benchmark of AGI progress.


The research labs have already exhausted the trillions of tokens of text data on the internet to get to the current generation of frontier models - scaling compute alone won’t produce the next breakthrough in model capabilities.
The pre-training scaling law may still have some room to run, but it’s now just one of the scaling laws, together with test time search, combining to deliver performance gains.
It is possible to stack “scaling laws” – pre-training will become just one of the vectors of improvement, and the aggregate “scaling law” will continue scaling just like Moore’s Law has over last 50+ years.
Dylan Patel, SemiAnalysiso3's improvement over the GPT series proves that architecture is everything. You couldn't throw more compute at GPT-4 and get these results. Simply scaling up the things we were doing from 2019 to 2023 – take the same architecture, train a bigger version on more data – is not enough. Further progress is about new ideas.
Francois Chollet, ARC Prize‘Internet Scale’ Reasoning Data
The GPT family of models performed poorly relative to o3 on the ARC benchmark because large models memorise knowledge rather than reasoning processes.
We are using these models for their intelligence, the language capabilities, the reasoning. But we're also using them at the same time as massive data stores that we as humans would Google things for. And so I suspect that I don't think it's going to require trillions of parameters one day to represent human intelligence. That very likely sits closer to the biological number of somewhere between 80 and 100 billion neurons at least.
Eiso Kant, CTO PoolsideAs an example, Meta intentionally overtrained Llama 3 on 15 trillion tokens to lower inference costs (as they served their billions of users). The model weights become more optimised for common patterns and in-distribution tasks, trading off generalisability to novel tasks.
This architecture combined with ‘internet scale’ data has produced incredible recent advances, but the next leap will come from a new paradigm - instead of outputs, models will be trained on reasoning steps.
The thing that was lacking is this multi-step complex reasoning in areas that we consider economically valuable. If that's a lawyer, if that's an accountant, if that's a developer, if that's a whole bunch of areas.
Now think about the web - the web doesn't actually have massive amounts of data representing multi-step complex reasoning because the web is an output product.
Eiso Kant, CTO PoolsideWe've been training these models off of the internet and the internet is like a set of documents which are the output of a reasoning process with the reasoning all hidden. It's like a human wrote an article and spent weeks thinking about this thing, deleting stuff, and then posted the final product and that's what you get to see. Everything else is implicit, hidden, unobservable.
So it makes a lot of sense why the first generation of language models lacked this inner monologue but now what we're doing with human data and with synthetic data we're explicitly collecting people's inner thoughts. We're asking them to verbalise it and we're transcribing that and we're going to train on that and model that part of the problem solving process.
Aidan Gomez, CEO CohereThis new vector of scaling will rely on a combination of synthetic and human generated reasoning data. As we’ll see, both will be expensive forms of reinforcement learning (o3’s performance of 87.5% on ARC AGI in high-compute mode cost thousands of $ per task).
Synthetic data
Synthetic data will be most useful for domains where functional verification is possible, e.g. code, maths and engineering.
Mathematics and code serve as natural testing grounds for AGI, much like Go—a closed, verifiable system where high intelligence can potentially be achieved through self-learning.
Liang Wenfeng, founder of DeepSeekScaling inference time compute is in line with the Bitter Lesson - there are only 2 techniques that scale indefinitely with compute: learning & search.
DeepMind’s AlphaGo used Monte Carlo Tree Search during test time to attain superhuman status - if stripped of this capabilities, it drops in Elo from ~5,200 to 3,000 (top humans are around ~3,800).
Dylan Patel articulated how language models produce synthetic reasoning tokens in functionally verifiable domains with a simple example:
I take an objective function. What is the square root of
81? If I asked many people what's the square root of 81 many could answer but I bet more people could answer if they thought about it more.
Let's have the existing model just run many permutations of this - start off with say five and then anytime it's unsure Branch into multiple.
So you have hundreds of "rollouts" or "trajectories" of generated data - most of this is garbage. You prune it down to these paths that got to the right answer - now I feed that and that is now new training data.
So I do this with every possible area where I can do functional verification, i.e. this code compiles, this unit test that I have in my code base, how can I generate the solution and how can I generate the function.
You do this over and over and over and over again across many many many different domains where you can functionally prove it's real, you generate all this data, you throw away the vast vast majority of it but you now have some chains of thought that you can train the model on which then it will learn how to do that more effectively.
Dylan Patel, SemiAnalysisThe exorbitant costs stem from the many, many Chains Of Thought generated as the model searches for the chains that lead to the right answer - all of the other tokens are useless, but cost a lot to generate.
For now, we can only speculate about the exact specifics of how o3 works. But o3's core mechanism appears to be natural language program search and execution within token space – at test time, the model searches over the space of possible Chains of Thought (CoTs) describing the steps required to solve the task, in a fashion perhaps not too dissimilar to AlphaZero-style Monte-Carlo tree search.
Effectively, o3 represents a form of deep learning-guided program search. The model does test-time search over a space of "programs" (in this case, natural language programs – the space of CoTs that describe the steps to solve the task at hand), guided by a deep learning prior (the base LLM). The reason why solving a single ARC-AGI task can end up taking up tens of millions of tokens and cost thousands of dollars is because this search process has to explore an enormous number of paths through program space – including backtracking.
Francois Chollet, ARC PrizeFunctionally verifiable domains are the most amenable to synthetic CoTs because engineering the reward is much easier than in domains where subjectivity is involved.
At poolside we don’t use customer data to train our foundational models – and we can do so thanks to our approach to improve models via Reinforcement Learning From Code Execution Feedback, or RLCEF. It allows us to push past the limit of available code and reasoning data 1, generating synthetic training data at scale.Domains where we have oracles of truth - and coding is frankly one of the largest and most powerful domains for oracles of truth, that's why we work in that area - you can generate different solutions to a task or problem and you can validate what is right and what's wrong.
Eiso Kant, CTO PoolsideCode execution provides an unambiguous, binary reward signal - either the code executes successfully or it fails, creating clearly defined success criteria for training.

In functionally verifiable domains, the correct CoT tokens become training data.
Over time, this should have a deflationary effect on the inference cost of reasoning models, as we’ve seen with frontier models in the pre-training paradigm.
If the answer is correct, the entire search trace becomes a mini dataset of training examples, which contain both positive and negative rewards.
This in turn improves the reasoning core for future versions of GPT, similar to how AlphaGo’s value network — used to evaluate quality of each board position — improves as MCTS generates more and more refined training data.
Jim Fan, NvidiaProcess and Outcome Rewards
There are two approaches to reward models: Process Reward Models (PRMs) and Outcome Reward Models (ORMs). PRMs enable granular evaluation by identifying specific failure points within reasoning chains, while ORMs assess the validity of the complete reasoning sequence through binary outcome validation.
ORMs are more scalable in functionally verifiable domains due to their inherent compatibility with automated verification processes.
OpenAI’s ‘Let’s Verify Step by Step’ paper produced stronger results for PRMs than ORMs, but acknowledged the challenge of scaling the human annotated 800,000 process steps (in maths).
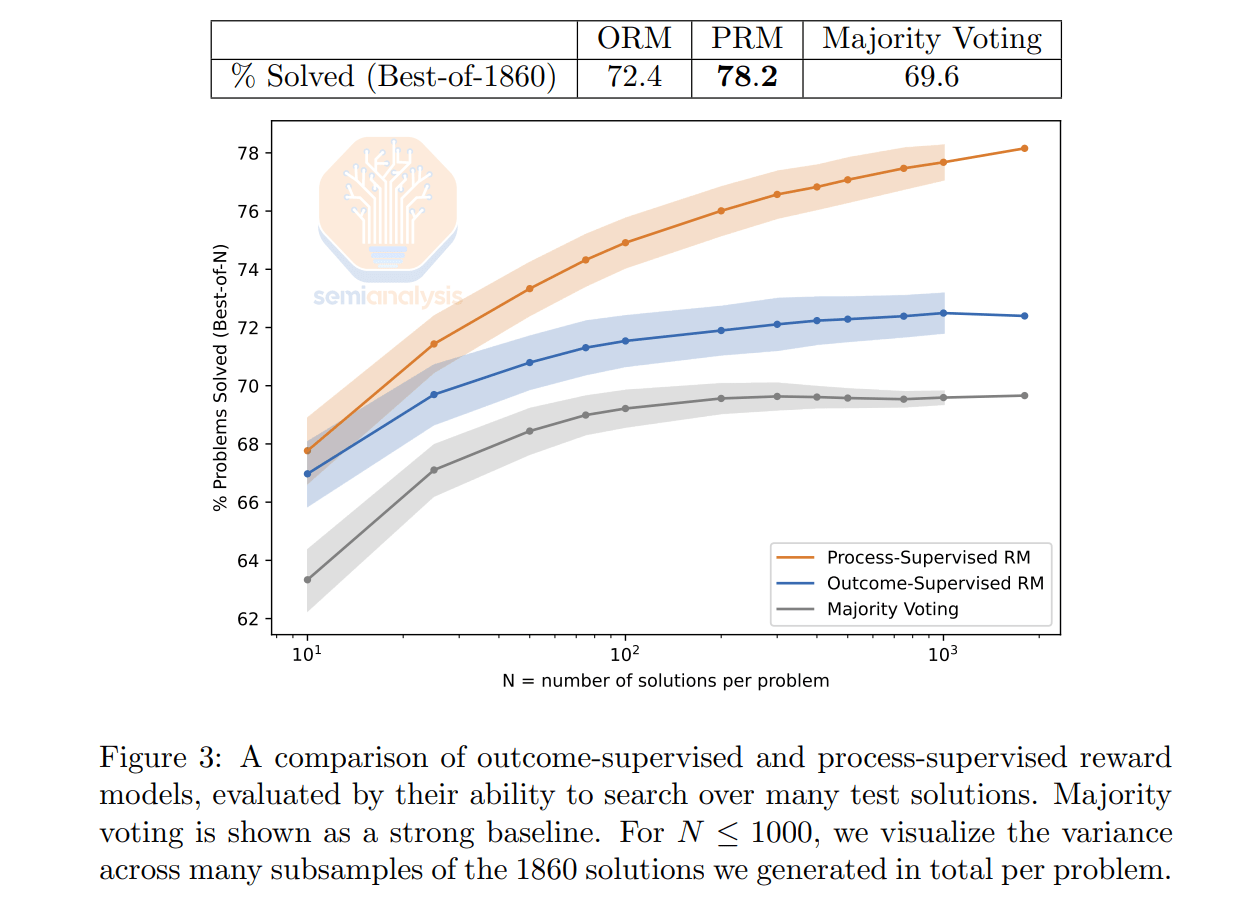
PRMs will be key to reasoning models replicating the same results they’ve shown in coding and frontier maths to other economically valuable tasks.
o3 made a breakthrough in solving the reward problem, for the domains that OpenAI prioritizes. It is no longer an RL specialist for single-point task, but an RL specialist for a bigger set of useful tasks.
Yet o3's reward engineering could not cover ALL distribution of human cognition. This is why we are still cursed by Moravec's paradox. o3 can wow the Fields Medalists, but still fail to solve some 5-yr-old puzzles
Jim Fan, NvidiaHuman Reasoning Traces
Progress in reasoning will naturally be faster in functionally verifiable domains where there is an ‘oracle of truth’ than domains with subjectivity where PRMs rely on human annotations to scale.
By the way, that’s one of the things the labs are spending money on generating is, “Can I get a lawyer to sit down and generate their reasoning traces for the conclusions that they write and can that be fed into the training data for a model and then make the models better at legal reasoning because it sees the whole process and not just the final answer?”
Nat FriedmanTo that end, vertical AI startups are investing heavily in collecting reasoning traces. Whether they hire their end users to label reasoning steps, or by using an outsourced vendors/marketplaces of human experts like Scale AI. Given that reasoning trace annotation requires deep domain expertise, the associated costs significantly exceed traditional computer vision labelling efforts, making in-house annotation efforts a material investment for startups.
Another area of research is how to represent subjective domains to be more like code - that is, to be functionally verifiable.
There's another way, which is how many problems and tasks that we want models to do as economically valuable work could actually be expressed as code.
Eiso Kant, CTO PoolsideLifan Yuan’s paper Reinforcement Learning through Implicit Rewards proposed to circumvent the need to label reasoning steps by using probabilities to estimate if each step was correct - however, this was only applied to Maths, for now.
Vertical AI startups across law, financial services, healthcare and other industries will need to employ all of the different reward model approaches to show time-to-value but increasingly mimic the reasoning process of humans. In practice, startups can start with ORMs and use proxies of success or failure to accelerate the training process and deliver the kinds of capabilities o3 is delivering in maths and code. In parallel, companies can invest in PRMs through a combination of in-house and third party labellers.
As these reward models continue to improve, transfer learning will also play a role in unlocking generalisation of reasoning capabilities.
'But in domains where we have oracles of truth, we're going to move faster than in domains where we don't, in domains where we don't have to gather it from humans. This is why you see massive investments from us and other companies in human-labeled data.
But I definitely do hold the suspicion - and there's early research already out there that shows that improved coding capabilities and reasoning towards coding does translate to other domains.'
Eiso Kant, CTO Poolside'The most important challenge within SFT is constructing sufficiently large, high quality data sets in the desired domains. This allows the model to operate better in specific areas like code, math, reasoning, and due to transfer learning, has spillover effects making the model better in other domains too.
Obviously, models with strong math and coding skills are better at general reasoning, but this extends to other areas – models trained on Chinese and English are better at English than those trained on English alone.'
Dylan Patel, SemiAnalysisConclusions
As pre-training gains plateau (or become too expensive), we’ve found a new vector of scaling (test time search) that is demonstrating a path to truly general intelligence.
Data acquisition/generation remains the bottleneck on progress, not compute. Microsoft’s announcement of $80bn in capex for 2025 underscores the Street’s underestimation of hyperscaler capex and compute buildout.
The implications of inference scaling run up and down the stack. Instead of the densely interconnected supercomputers of the pre-training paradigm, we will see more distribution of workloads, perhaps some even running locally. How will market share evolve as companies look to optimise test time search workloads - will AI ASICs eat into Nvidia market share?
Instead of prohibitively expensive pre-training runs, enterprises developing their own models may opt to train smaller models with reasoning cores and decide when to scale up test time search for certain economically valuable tasks. The result is the alchemy of capex to opex and fixed costs to variable costs. CIOs will decide which tasks merit more investment and test time search - inevitably, this will still be cheaper than human labour.
While significant research challenges remain to transfer these capabilities to other domains, the emergence of these new scaling laws justifies optimism about continued advancement.
I’m in in New York this week - reach out if you’d like to grab a coffee!
Thank you for reading. If you liked this piece, share it with your friends.
Good high level overview. I am skeptical of the efficacy of tts.