



Reassessing Incumbent Data Gravity In AI
Iceberg And Open Table Formats Commoditise Storage

👋 Hey friends, I’m Akash! Software Synthesis is where I connect the dots on AI, software and company building strategy. You can reach me at akash@earlybird.com!
If you’re looking to join a hugely exciting vertical AI seed company and the below applies to you, please send me a message:
Mid/senior full-stack developer
Based in London
Interested in multimodal AI and agentic workflows
One of the main arguments for AI value creation accruing to incumbents is data gravity.
Speaking to Ben Thompson about Salesforce’s right to win AI workloads, CEO Marc Benioff said:
If you’re going to get these agents to work, you want these agents to work, what do you need? What are the ingredients? Let’s say we’re making a cake. You want an LLM, but that’s just like sugar. That’s going to make it great, okay, you’re going to have to have a pretty advanced RAG technique. You’re also going to need data because LLMs by themselves don’t know anything, they’re just an algorithm, you’re also going to want metadata because the data is better if it’s explained to the LLM what the data and metadata are.
On the other side, I could say we always felt that the beginning with our Platform as a Service approach, which is a term I actually came up with back in the late ’90s, that the platform would always carry us through that, the fundamental truth of our industry over many years is it’s not about the app because the apps tend to be very temporal, but really it’s about the platform and the data over time.
It’s why Salesforce has been investing heavily into its Data Cloud, built on Apache Iceberg. At last month’s Dreamforce it became clearer to partners and customers that adopting Data Cloud is key to realising the vision of Agentforce that Marc Benioff laid out - Data Cloud is now the fastest growing product in Salesforce’s history.
As more public company CEOs like Marc Benioff switch into founder mode, it’s worth investigating just how powerful their data gravity really is.
Iceberg neutralises data gravity
80-90% of all new data generated is unstructured, and most of of the 175 zettabytes of data we’ll have by 2025 will be unstructured.
Tabular (acquired by Databricks) founder Ryan Blue on the importance of open table formats:
Open table formats are the next foundational innovation. These make it possible to build universal storage that is shared in place (zero-copy) between as many different compute frameworks as you need — from high-performance SQL engines to stream-processing applications and Python scripts.
The pull of data gravity is strong and creates a natural lock-in that can be paralyzing. Creating a universal storage layer breaks down the silos and enables you to use the right tool for the job, and adopt new tools more easily.
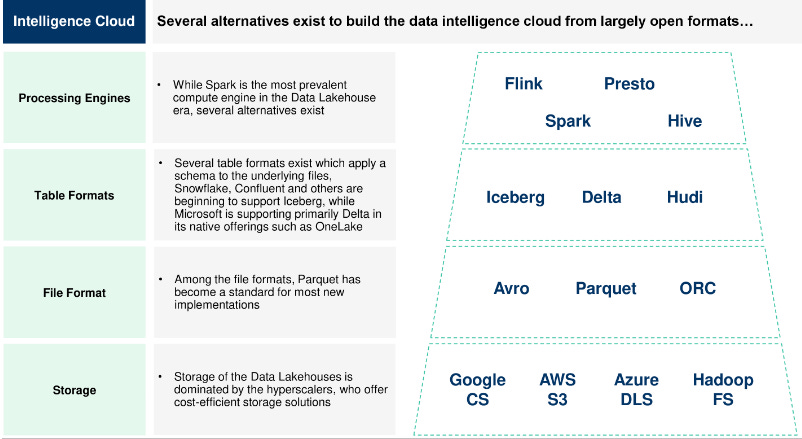
The bundling of storage, transformation and compute has been key to data lakehouse lock-in for Databricks and Snowflake. Consolidation around open table formats like Iceberg (and Hudi/Delta Lake to a lesser extent) will gradually result an unbundling of each of these components - with Iceberg, companies can store data cheaply with their preferred cloud providers’ storage without copying it for different query engines like Flink, Spark.
Databricks’ position is that any threat to storage revenue implied by Iceberg having won the table wars is more than offset by the lock-in from their Unity Catalog, which controls access rights and governance across Databricks’ entire product suite.
The trend of CIOs actively neutralising data gravity is clear.
Customers all want Iceberg, they all want to be able to have their own data…you can understand why, so they don’t have to pay for the cost of storage twice….Nobody wants to get locked in on their data. Everyone wants to have their data in open file formats, that it’s easy to move the data out and in….makes it cheaper to run your queries on that. Snowflake CFO
It’s why Salesforce decided to federate their Data Cloud to be able to connect with any data source inside their customers:
In the last few years, what I was mostly excited about was we’ve built this incredible data cloud on top of all those customer touch points that federates, which means it can connect into any other data repository, lock it in and bring the data together. But then I just laid this agentic layer on top of the data cloud and boom, customers are having this unbelievable experience and this experience is their costs are going down, their employees are highly augmented.
So the data cloud federates to other data sources, and that’s very powerful. It can go off to mainframes, it can go off to other data lakes like Snowflake’s, Databricks, yes, even the Microsoft one, the Google one, the Amazon one, and your proprietary ones as well. We bring it all in and then we build a canonical model.
As Palantir ascends to a >30x EV/NTM multiple, it’s worth underlining this passage from Nabeel Qureshi’s reflections:
Another key thing FDEs did was data integration, a term that puts most people to sleep. This was (and still is) the core of what the company does, and its importance was underrated by most observers for years. In fact, it’s only now with the advent of AI that people are starting to realize the importance of having clean, curated, easy-to-access data for the enterprise.
In simple terms, ‘data integration’ means (a) gaining access to enterprise data, which usually means negotiating with ‘data owners’ in an organization (b) cleaning it and sometimes transforming it so that it’s usable (c) putting it somewhere everyone can access it. Much of the base, foundational software in Palantir’s main software platform (Foundry) is just tooling to make this task easier and faster.
The premise of agents rests on read/write access to clean, unified enterprise data (as we’ve discussed before). Much of the required access will come from engineering integrations, and some of it will come by wrangling it from sensitive data owners (as Palantir has often had to navigate).
Open table formats commoditise storage as the Fortune 500 slowly but surely moves their data towards Iceberg.
Palantir, Salesforce, Databricks, UiPath and several other software giants are vying for the goal of being the connective tissue that unifies data and enables agentic applications to be built, with each claiming a different right to win the ‘computation engine’ AI workloads.
Palantir’s FDE model helps them integrate gnarly sources of data, whilst Salesforce is building their own models and investing heavily in context-retrieval with claims of having the least hallucinogenic model in the market. Databricks’ M&A activity (Tabular, Lilac, Mosaic) help it lay a claim as the full stack AI infrastructure company. UiPath’s positioning is to be the orchestration engine for agents, providing agents with the necessary context about business processes.
The public markets have rewarded Palantir’s flavour of data gravity the most, likely due to the gnarly nature of the data integrations Foundry has been built on. A >30x multiple affirms that data gravity does matter.
But we risk ascribing too much gravity to incumbents.
Thank you for reading. If you liked this piece, please share it with your friends, colleagues, and anyone that wants to get smarter on startup strategy. Subscribe and find me on LinkedIn or Twitter.