



Open Questions About AI
LLM OS, Dense vs MoE, Market Structures, Agents and Applications

Hey friends! I’m Akash, partnering with founders at the earliest stages at Earlybird Venture Capital.
Software Synthesis is where I connect the dots on software and company building strategy. You can reach me at akash@earlybird.com if we can work together.
Current subscribers: 4,780
Inspired by Elad Gil’s ‘Things I Don’t Know About AI’, I’m listing out the questions that I’ve been thinking about and discussing with founders/researchers lately.
The LLM OS War
Andrej Karpathy was one of the first to describe the notion of an LLM OS. The great team at
reclassified the RAG/LLMOps war into the LLM OS war, which encompasses all of the LLM infra/tooling that’s emerged in the last two years.

How do AI inference clouds differentiate? If GPU-as-a-service is a race to the bottom, where do these companies expand their product suites? Fine-tuning-as-a-service is the adjacency that’s already supported. Companies like Fireworks are selling ‘compound systems’, investing in better function-calling models and quantisation to deliver AI outcomes for their customers.
Will LLM observability spend be captured by existing ML observability tools? For enterprises already using ML observability tools, where ML use cases represent the majority of their AI models compared to GenAI (e.g. in financial services), how can LLM observability vendors become best-of-breed in a tangible way to justify the extra outlay?
Hardware optimisation for LLM training and inference is still nascent - companies like Foundry are early frontrunners offering developers maximum efficiency.
Model Architectures
Will the build out of transformer-specific infra (e.g. AI ASICs like Etched) cement its lead as the dominant model architecture or will alternative architectures like State Space Models (and others) attract sufficient capital to generate their own ecosystem of tooling? The trade offs inherent to different architectures suggests there will be use cases where the use case-architecture fit will favour some architectures beyond just transformers.
Which architecture will prevail between Dense and Mixture of Experts?
Deepseek’s impressive performance is in part attributable to their MoE architecture with 160 experts (in general Chinese labs like Alibaba, Zhipu and Deepseek have had to maximise computational efficiency given export controls on Nvidia semis since 2022). At inference, 6 experts are activated, activating 21 billion parameters out of a total of 236 billion parameters.
Snowflake’s Arctic, positioned to be a leader in SQL and code generation, has 480 billion parameters spread across 128 experts, with 17 billion active parameters. To deliver best-in-class ‘enterprise intelligence’, Snowflake used a hybrid Dense-MoE architecture.
Meta’s recent Llama models sparked debate given the extent of pre-training well beyond Chinchilla optimal - they’ve also eschewed MoE in favour of a straightforward dense transformer.

Agents
Will agents distributed by Big Tech solidify their position as the Aggregators of the internet? Browserbase, Anon and other agent infra companies herald a future where the majority of web traffic will be agents - will APIs and websites be reformatted for easier consumption of Gemini’s agents, as content marketing is optimised for Google SEO?
Are ‘large action models’ truly a distinct subset of foundation models with a different training data set? On closer inspection, are the ‘action’ capabilities stemming from post-training using RL data and a reward model to align the base model for automation (as Misha Lasky of Reflection suggested)?
Is the ‘large action model’ category a modality where the bitter lesson applies and is therefore inevitably going to consolidate into a handful of models capable of expending the capex dollars required to remain at the frontier?
Foundation Model Market Structure
How do companies competing in voice, video, audio, etc. maintain their performance edge once the large research labs channel their R&D towards a specific modality (as is now happening in video)? The acquihires of Inflection, Adept and Character.ai support the narrative that large model training is the province of a handful of companies with Big Tech sponsors. Will durability come from workflows rather than model performance?
Meta’s uniquely positioned to continue closing the gap on proprietary closed-source models given their business model - it’s no wonder Anthropic has made so many product hires . If open source models end up commoditising frontier model capabilities and AI inference clouds abstract away development complexity, will closed-source model providers need to move upstream into applications?
Even if hyperscaler capex is excessive relative to near-term revenue potential, Google and Microsoft are antifragile in that they can at least be the customers of that compute (training/inference for their own models and apps like Google Workspace and Microsoft Copilot) whilst AWS is fully indexed on the wider AI app ecosystem, which is more brittle and will eventually consolidate. What will Amazon do to ensure they can capture spend at the application layer?
Applications
Do horizontal AI apps differentiate through more opinionated UI/UX, sheer product velocity (faster time to nth product as a compound startup), outcome-based pricing, or reliability? Are there any fundamental differences to the Application SaaS paradigm, except for the ostensible data gravity enjoyed by incumbents?
Given Harvey tried to acquire a legal research database (as well as other recent acquisitions like Preqin underscoring the value of data businesses, more insights on data businesses here), is excitement in vertical AI mostly centred around AI-native companies acquiring data before databases can offer AI capabilities?
I’d love to hear the questions and thoughts you’re thinking through.
Charts of the week
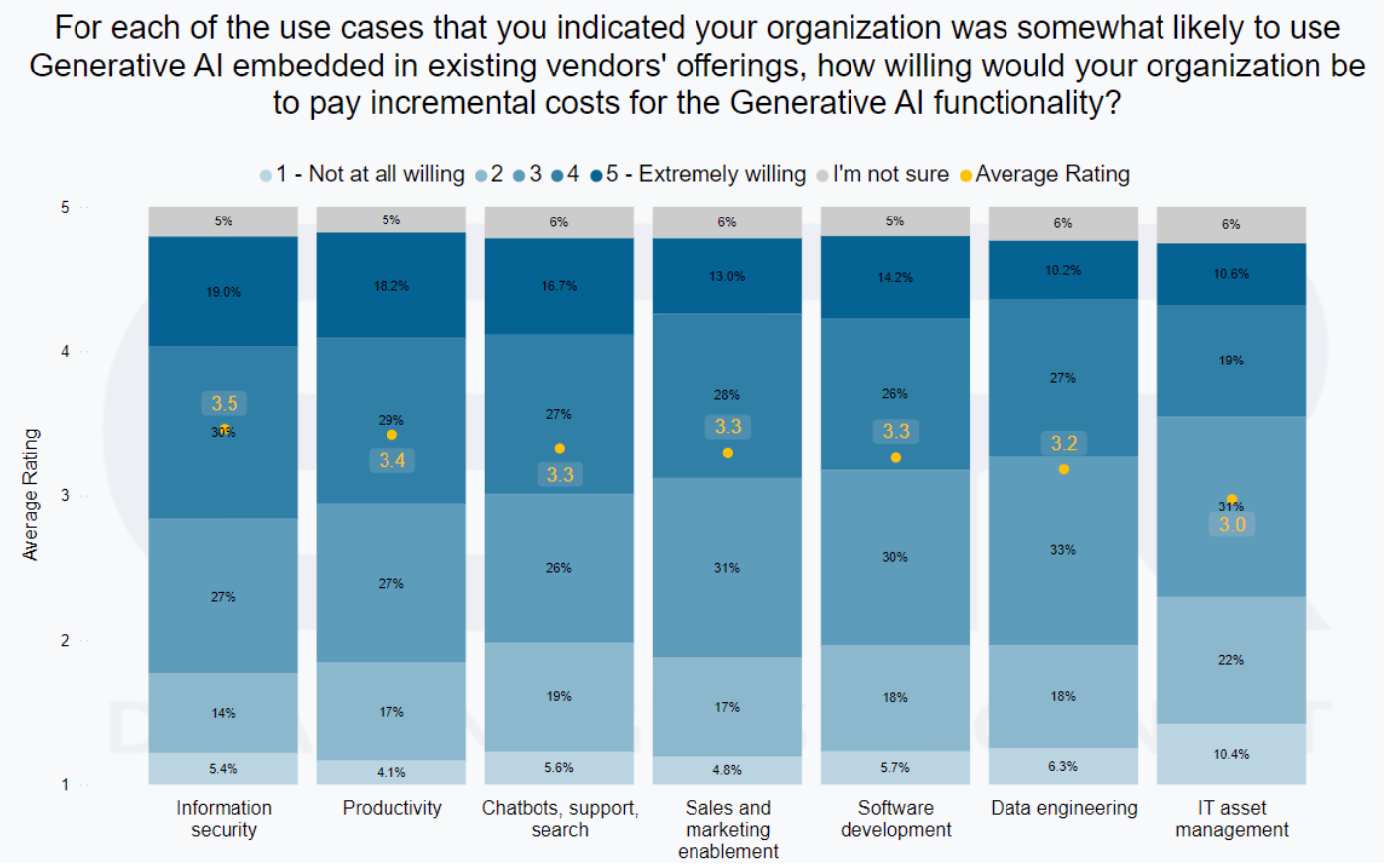
Information Security and Productivity are the categories with the highest willingness to pay for AI SKUs
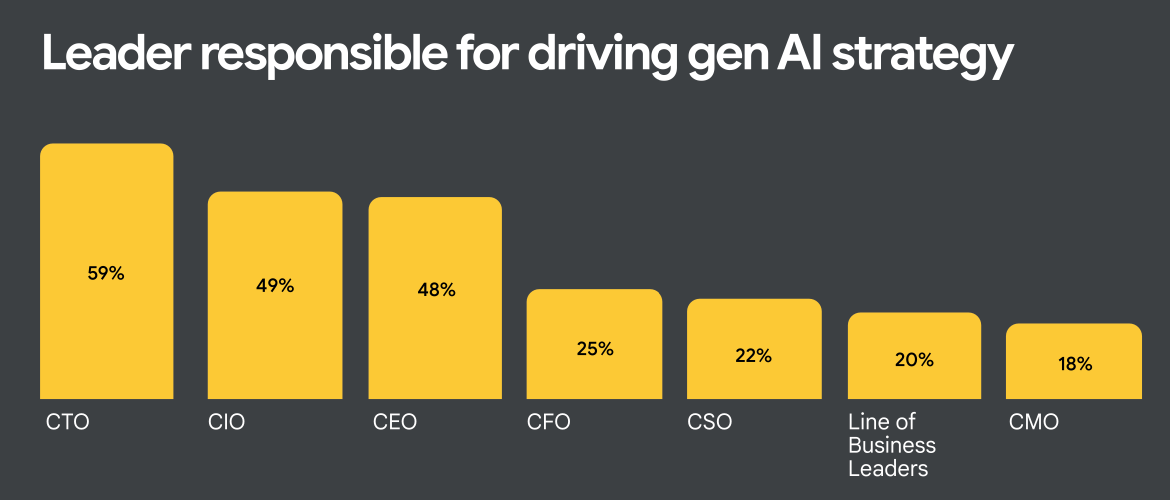
CTOs are primarily responsible for driving GenAI initiatives in the enterprise
Lack of DPI from recent venture vintages is stark

Curated Content
The AI Supply Chain Tug of War by Sequoia
The Genius of PostHog Marketing by Battery Ventures
UK's elite hardware talent is being wasted. by Josef Chen
Things that Used to be Impossible, but are Now Really Hard by Tomasz Tunguz
Flox by
Quote of the week
‘As a corollary, since the instruction set of a neural network is relatively small, it is significantly easier to implement these networks much closer to silicon, e.g. with custom ASICs, neuromorphic chips, and so on.
The world will change when low-powered intelligence becomes pervasive around us. E.g., small, inexpensive chips could come with a pretrained ConvNet, a speech recognizer, and a WaveNet speech synthesis network all integrated in a small protobrain that you can attach to stuff.’
Thank you for reading. If you liked it, share it with your friends, colleagues, and anyone that wants to get smarter on startup strategy. Subscribe below and find me on LinkedIn or Twitter.