



Continued Vertical AI Integration, Diffusion LLMs and Application AI Moats
Integrating software and hardware, capabilities unlocked by dLLMs, Granola's lessons for enduring value and progress in planning

Hey friends, I’m Akash! Software Synthesis analyses the evolution of software companies - from how they're built and scaled, to how they go to market and create lasting value. Join thousands of readers that are building, scaling, or investing in software companies. Reach me at akash@earlybird.com to exchange notes.
Good morning.
On today’s update, we discuss the continued vertical integration of AI, diffusion-based LLMs, moats at the application layer and chain-of-continuous-thought.
On to the update.
Meta goes full-stack
Big Tech continues to ramp up capex in a version of Pascal’s wager.
 to $105B (2025), Microsoft $55.7B (2024) to $94B (2025), Alphabet $52.5B (2024) to $75B (2025), and Meta $39.2B (2024) to $65B (2025).")
Mark Zuckerberg outlined a bold vision for Meta’s leadership in AI in the Q4 2024 earnings call, commenting on future Llama models, glasses as new computing platforms and infrastructure investment.
On AI development trajectory:
I expect that 2025 will be the year when it becomes possible to build an AI engineering agent that has coding and problem-solving abilities of around a good mid-level engineer. This is going to be a profound milestone and potentially one of the most important innovations in history.
On infrastructure investment scale:
These are all big investments -- especially the hundreds of billions of dollars that we will invest in AI infrastructure over the long term. I announced last week that we expect to bring online almost 1GW of capacity this year, and we're building a 2GW and potentially bigger AI datacenter that is so big that it'll cover a significant part of Manhattan if it were placed there.
On open source AI leadership:
I think this will very well be the year when Llama and open source become the most advanced and widely used AI models as well... our goal for Llama 4 is to lead.
On AI glasses as computing platforms:
I previously thought that glasses weren't going to become a major form factor until we got these -- the full kind of holographic displays that we started showing in the prototype for Orion. But now I think it's pretty clear that AI is actually going to drive at least as much of the value as the holographic AR is.
On product monetisation strategy:
We build these products. We try to scale them to reach usually a billion people or more. And it's at that point once they're at scale that we really start focusing on monetisation.
Scaling is already underway as a claimed 700 million monthly users access Meta AI’s capabilities via Whatsapp and Facebook, but now the company is working on a standalone app that Zuckerberg hopes will become the leading AI chat app in the world. This is of course in parallel with continued investment in Orion, which can lay a claim to finally being the bridge from the smartphone to the next computing platform (due to native AI applications that are inherently superior when deployed in smart glasses rather than phones).

Mistral’s productisation of its models via Le Chat was perhaps the most telling move from a foundation model company that the future lies in being full-stack - but where the frontier labs can integrate models and apps, big tech can integrate hardware, too.
Amazon’s updated Alexa will use both its own family of Nova models and Anthropic’s models (where they’ve invested >$8bn). Amazon of course adheres to model commoditisation - as a buyer of tokens in an oversupplied market, it’s well placed to abstract away underlying models, especially when incremental model capabilities aren’t material to end consumers:
What Amazon seems to be doing with Alexa is creating a value capture sandwich with the commoditization of simple models in the middle. A smarter Alexa with a more meaningful usage-based COGS is part of the now-standard Amazon model of offering a bundle, continuously expanding it, occasionally raising the price, and then sometimes splitting off a cheaper plan.
Ultimately, all of the labs are racing to own the end consumer by becoming product companies. OpenAI was endowed with an advantage because of ChatGPT’s accidental success but that hasn’t stopped them from working a phone with Jony Ive.
Going full-stack in software is one thing, but combining hardware and software might be the way that end consumer mindshare is truly won.
Alan Kay’s famous words used to be recited by Steve Jobs and more lately Carl Pei, CEO of Nothing:
People who are passionate about software should make their own hardware.
Diffusion LLMs
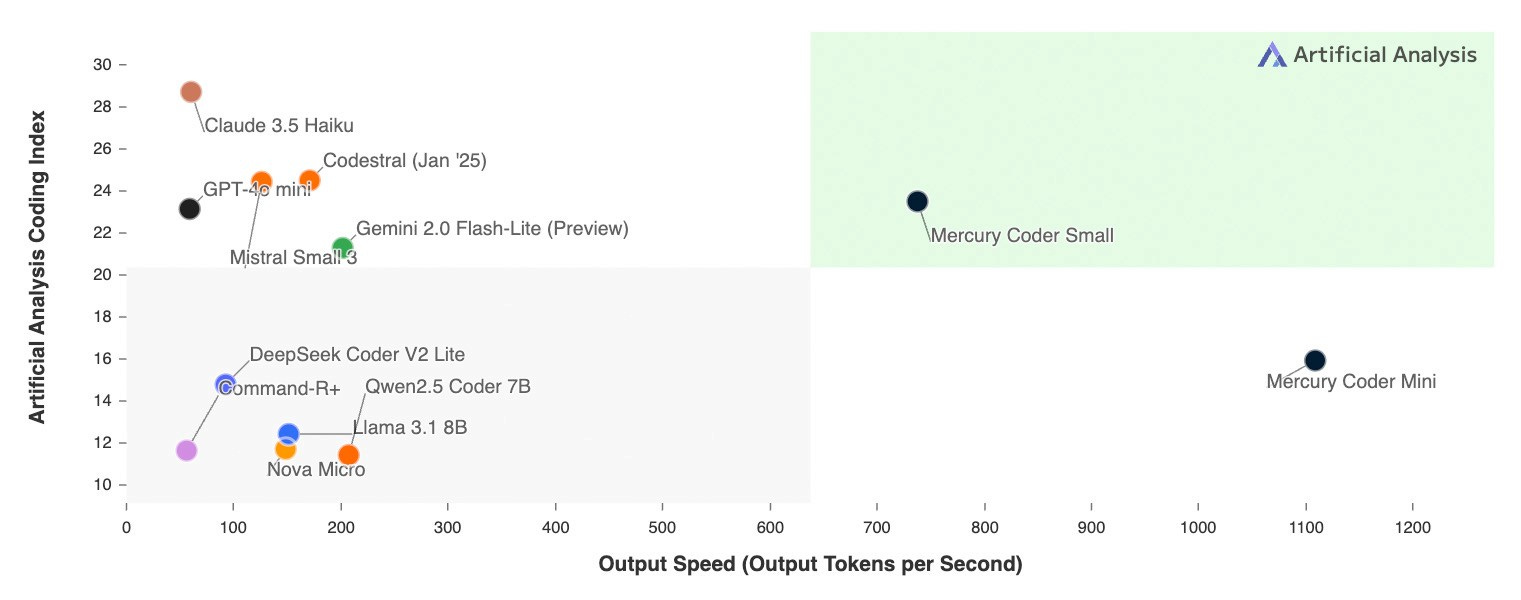
Inception Labs released Mercury on 26th February, a diffusion-based LLM that is supposedly 10x faster on speed-optimised LLMs, even when running on commodity H100s.

Diffusion generation is generally associated with image and video-gen models, but the Inception Labs team has applied diffusion generation to text to yield incredible results. The founding team are professors from Stanford, Cornell and UCLA and are behind innovations like Flash Attention, Decision Transformers, and Direct Preference Optimisation.
Diffusion-based generation differs from auto-regressive generations in that they can update multiple tokens at once.
To bring this to life, here’s an example Claude served me up with. Auto-regressive generation renders one token at a time, strictly from left to right, with each new token relying only on previously generated tokens.
Step 1: "" → "The"
Step 2: "The" → "The cat"
Step 3: "The cat" → "The cat sat"
Step 4: "The cat sat" → "The cat sat on"
Step 5: "The cat sat on" → "The cat sat on the"
Step 6: "The cat sat on the" → "The cat sat on the mat."
Mercury’s approach starts with noise and then refines it in steps, with multiple tokens changing in each step:
Step 1: "The zat plm on the yat."
Step 2: "The cat sat on the yat."
Step 3: "The cat sat on the mat."
Combine diffusion with commoditised hardware that enables parallelisation and you have much faster inference - try it out for yourself (toggle on the Diffusion Effect to really appreciate the magic). Given the fanfare for Le Chat’s inference speed (powered by specialised hardware in Cerebras), this is truly impressive.
A criticism of autoregressive models is that they can’t really do long time-horizon planning, certainly not the kind one would expect of an AI worker where it has to grapple with the real world’s complexity (which is not fully observable, not deterministic, continuous, and high dimensional).
Whilst Mercury is still a transformer-based model using diffusion for generation, it’s interesting to think about applications unlocked by state space models that use diffusion. SSMs use state vectors to capture dependencies in a sequence rather than the attention mechanisms that transformers use - it’s why the compute requirements for SSMs scale linearly rather than the quadratic scaling of transformers.
SSMs that use diffusion for generation could marry these properties to deliver:
Streaming diffusion generation: a diffusion-SSM could allow for continuously refining generated text while receiving ongoing input, enabling truly adaptive real-time generation.
Multimodal processing: SSMs could efficiently process temporal streams (audio, video) while diffusion handles global refinement across modalities, potentially creating more efficient multimodal systems.
Back to Inception Labs - the company claims customers in applications like customer support, code generation, and enterprise automation, who are ostensibly opting for dLLMs as they no longer have to trade-off performance for latency.
The dust hasn’t settled yet on this release so it’s too soon to assess scaling laws for dLLMs or how Inception Labs plans to counterposition against frontier labs, but this is definitely one of the more exciting developments at the model layer.
Application Layer Moats
As a Granola DAU, I was pleasantly surprised to see Invest Like The Best release an episode with Christopher Pedregal, cofounder and CEO.
As one of the lean AI-native companies of this generation, Granola is one of the best examples of how taste and opinionated software will thrive even as model companies become full-stack. Chris shares wisdom on building enduring value at the application layer that are applicable to most founders building for end consumers.
On UI/UX:
I do think a huge blocker for unlocking the power of collaborating with AI is what's the UI? What's the interface for collaborating with UI? I really think we're in the terminal era with multiple computers where you type in a command and then the computer would literally spit back a command. The way we work with ChatGPT, I don't think chat's going away, but I think it will feel archaic.
Right now we have some very coarse controls and it's turn taking. Right now it's like I write something, then the AI does something, then I react back to it. And I think it's going to be a lot more fluid and a lot more collaborative once we figure that out.
On building value on top of foundation models:
For us, we build on top of foundation models and the speed at which models have gotten better over the last three years is incredible. And I believe that companies like Granola benefit tremendously from the competition between the providers. And as a result, I think users are benefiting tremendously.
Value accrual in the AI stack:
I think everything that is low frequency, where you don't need to be great at it, will be eaten up by the general system.
the other end of that quadrant is basically high frequency use case where your output needs to be really, really good. And that's basically the power tool quadrant. There'll always be that pro tooling for the people who really want to do a fantastic job at something. I think that's where Granola sits.
It's not a question of intelligence, it's actually how great is the UI optimized for this use case? And I think that if you have a product that is solely dedicated to being phenomenal at that use case, it will be a better experience than a general tool will be. So I think the limitations there, what separates that is really around the product design and optimisation of the user experience, not of the underlying technology.
The laser-focus on user experience and product design wins the right to be the system of engagement for the end user. This, in turn, allows the vendor to hoover up data and relegate existing systems of record to obsolescence.
Tidemark published a note on how vertical software winners will earn a right to consolidate data by owning the analytics and reporting layer - I would argue the same applies to horizontal software:
SAP was scared sh*tless about becoming the “system of ledger” in the back closet. It’s like the system of record where everything is stored and extracted, but rarely used. Over time, Hasso (SAP co-founder and then chairman) rightly worried that SAP would lose account ownership and the ability to cross-sell. Their answer? Hire IDEO to bring the UI into the 2000s (I am old) and look at buying a BI tool. My summer project involved creating many slides—which were rated substandard—to make the argument. They ended up buying Business Objects in 2007 for $6.78 billion.
This time, though, the wave isn’t cloud computing–it’s generative AI. A new wave opens new profit pools and new vectors for attack. Users can interact with your software differently through chat and voice interfaces, data previously locked up in PDFs is suddenly freed, and the opportunity is greenfield. VSaaS companies can either grow or be relegated to becoming the system of ledger that GenerativeAI applications use to pull their data from.
AI apps in the top decile of engagement will very quickly amass a first-party dataset (e.g. transcriptions for Granola, generated code for Cursor) that confers a right to become the OS for end users, whether that’s a small business owner or a team in an enterprise. To add to that, MCP servers make data interoperable - read/write actions can be orchestrated from the tool of your choice. Combine this with third party data and you have inescapable data gravity for AI apps.
This is of course trivialising the perils of selling into the enterprise, where most apps are still early in penetration. That won’t stop their march downmarket, though.
As AI apps look for new levers to unlock growth, there’s more to be said about product-led onboarding for AI apps: Kyle Poyar’s newsletter has a good analysis of Cursor, Replit and Bolt’s hacks on this front.
Coconut - Chain Of Continuous Thought
CoT tokens are by now a well understood way to give models reasoning abilities by breaking down objectives into discrete steps. Until now, these CoT tokens were represented as words.
Shibo Hao, Sainbayar Sukhbaatar, and researchers at Meta and University of California San Diego introduced a method that trains LLMs to process chains of thought as vectors rather than words and enabling them to reason in a continuous latent space.
The model starts with traditional CoT reasoning and gradually replaces language reasoning steps with continuous thoughts. These continuous vectors can store more information than single language tokens - they can represent multiple potential reasoning paths simultaneously.
This ability to effectively search through multiple reasoning paths is similar to breadth-first search:
Continuous thoughts can encode multiple potential next reasoning steps simultaneously
The model maintains several possible paths and progressively eliminates incorrect ones
This contrasts with CoT's single deterministic path
Vector representations of reasoning steps presents interpretability challenges but the potential upside far outweighs these concerns. These findings hold lots of promise for planning-intensive tasks that are just out of reach of current SOTA agents, and aligns with cognitive theories that humans often reason without explicitly verbalising each step, instead maintaining "mental models" that explore multiple possibilities.
Jobs
Companies in my network are actively looking for talent:
An AI startup founded by repeat unicorn founders and researchers from Meta/Google is building 3D foundation models and is looking for a ML Training / Inference Infrastructure Engineer with 3+ years of experience in a cloud-related role, preferred ML-related (London or Munich).
A Series A company founded by early Revolut employees is building a social shopping platform and is looking for Senior Backend, Frontend and Fullstack Engineers and Business Development Managers across Europe (London, Toronto, France, Germany, Spain, Italy, Remote).
A vertical AI startup tackling the accounting industry is looking for a founding GTM hire (London).
Reach out to me at akash@earlybird.com if you or someone you know is a fit!