



Concentration In The AI Value Chain
Market Structure Evolution & Implications For Pricing Power

👋 Hey friends, I’m Akash! Software Synthesis is where I connect the dots on AI, software and company building strategy. You can reach me at akash@earlybird.com!
One of the statistics that raised eyebrows in Nvidia’s most recent quarterly earnings was its customer concentration - 46% of revenues came from just four customers.

It doesn’t take much guessing to figure out who those four companies are.
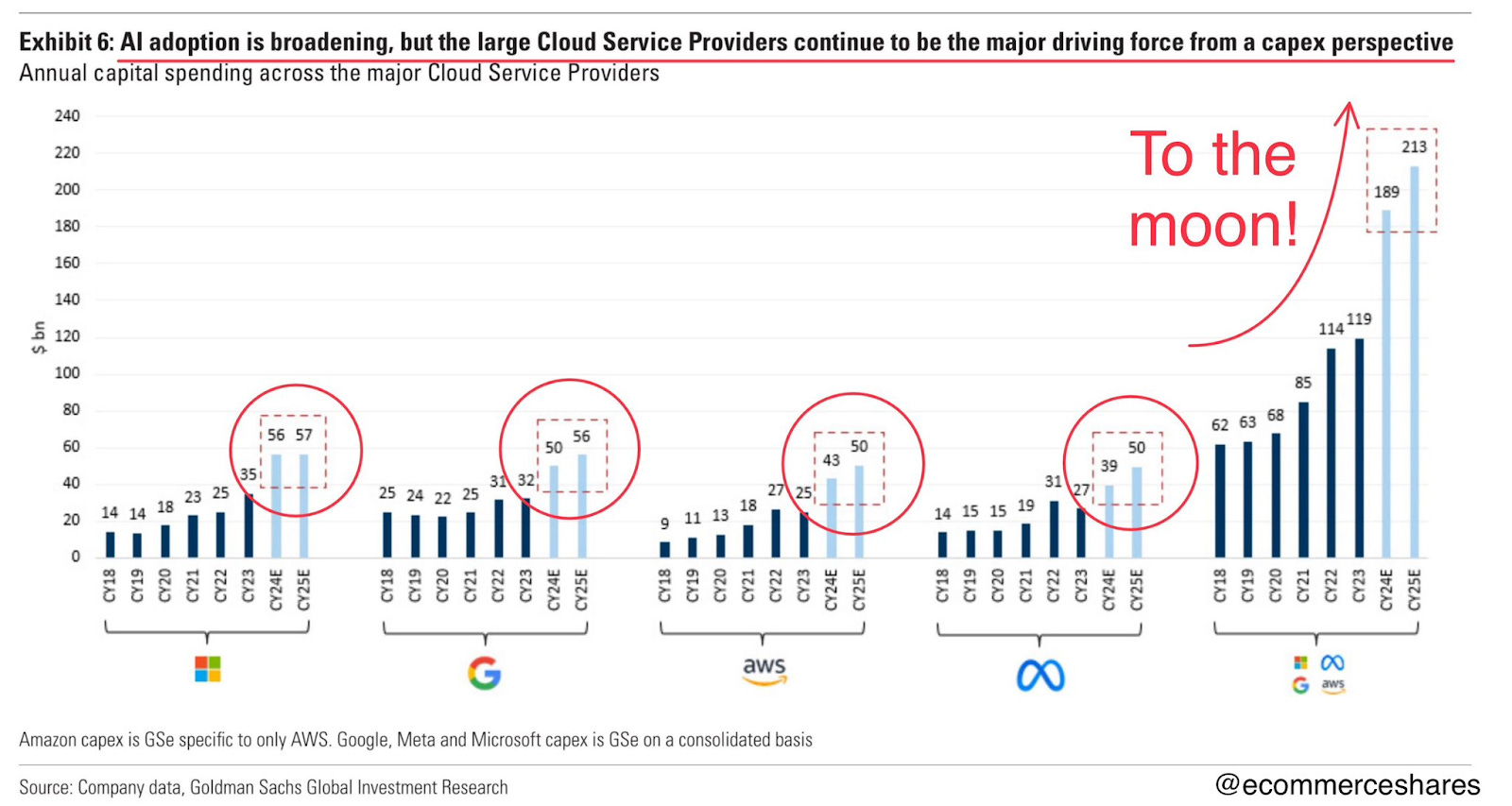
MSFT, AMZN, META and GOOGL are ramping up capex to the hundreds of billions because they’re locked in a capital arms race - the stakes are so high that investment from one hyperscaler elicits a response from the other.

Even so, that degree of customer concentration is why there’s so much discourse around Nvidia’s moats.
Why is customer concentration bad?
Bill Gurley put it best in his timeless post ‘All Revenue Is Not Created Equal’:
In their S-1, companies are required to highlight all customers that represent over 10% of their overall revenue? Why do investors care about this?
Once again, all things being equal, you would rather have a highly fragmented customer base versus a highly concentrated one. Customers that represent a large percentage of your revenue have “market power” that is likely to result in pricing, feature, or service demands over time. And because of your dependence on said customer, you are likely to be responsive to those requests, which in the long run will negatively impact discounted cash flows. You also have an obvious issue if your top 2-5 customers can organize against you. This will severely limit pricing power.
Brad Gerstner pressed CEO Jensen Huang on the threat from the hyperscalers’ own efforts to develop custom AI hardware during the interview BG2, to which Jensen confidently admitted that Nvidia even shares their longer-term roadmap with them:
Notice my roadmap is transparent at GTC. My roadmap goes way deeper to our friends at Azure and AWS and others. We have no trouble doing any of that even as they're building their own ASICs.
The singular purpose of the company is to build an architecture that—a platform that could be everywhere, right? That is our goal. We're not trying to take any share from anybody. Nvidia is a market maker, not a share taker.
In claiming that ‘demand is insane’, Nvidia’s implied position is that market for training and especially inference is going to grow at such a rate that any threat from AI ASICs is missing the bigger picture of market expansion. It’s why Jensen heaped praise on Elon Musk’s ability to build the biggest supercomputer with a 100k H100 cluster in 19 days, even as Elon has been explicit about doubling down on Tesla’s own supercomputer Dojo to compete with Nvidia.
Concentration In The AI Stack
One of Nvidia’s main competitors for training and inference workloads, Cerebras, revealed a staggering 87% of revenue coming from G42.
Customer concentration is most acute at the lower levels of the AI stack where we’re interacting with atoms - yield curves matter.

Semis
ASML has a monopoly on the EUV lithography equipment needed for leading edge chips and ought to be a price maker, but itself also has high customer concentration with TSMC, Intel and Samsung accounting for >80% of revenue.

Despite beating analyst estimates in Q3’24 earnings, ASML saw a sell-off last week owing to weaker forward guidance. Citing weakness from Intel and Samsung, CEO Christophe Fouquet said:
Today, without AI the market would be very sad.
Fortunately TSMC beat Q3 estimates and also projected rosier forward-looking numbers.
TSMC’s customer concentration isn’t as high as ASMLs, but its still clearly exposed to the same headwinds and tailwinds - its top 10 customers account for c. 70% of revenue, with Apple and Nvidia being the top two.
CEO CC Wei effectively answered AI’s $600B question on the earnings call:
Simply, whether this AI demand is real or not. Okay. And my judgment is real. We have talked to our customers all the time, including our hyperscaler customers who are building their own chips. And almost every AI innovators is working with TSMC. And so we probably get the deepest and widest look than anyone in this industry.
And why I say it's real? Because we have our real experience. We have used the AI and machine learning in our fab, in R&D operations. By using AI, we are able to create more value by driving greater productivity, efficiency, speed, qualities.
And think about it, let me use 1% productivity gain. That was almost equal to about $1 billion to TSMC. And this is a tangible ROI benefit. And I believe we are -- we cannot be the only one company that have benefited from this AI application. So I believe a lot of companies right now are using AI and for their own improving productivity, efficiency, and everything. So I think it's real.
The ROI is real.
It might take time for AI’s efficiency and productivity gains to diffuse across the global economy, but it sure will.
The ROI of over-investing in the lowest levels of the AI stack needs to be measured against the eventual market size further up the stack, as well as further market consolidation and the pricing power that will follow.
Foundation Models
A crude way to project market structure evolution would be to fully rely on the scaling laws, which would see a consolidation to a handful of players across modalities that are capable of paying the sums needed for larger supercomputers and scarce training data.
posited another lens for market structure evolution:I proposed a framework centered on demand nuances and innovation generalizability to evaluate the intensity of potential consolidation.
For instance, the AI video generation market could remain fragmented for longer compared to the AI code generation market due to a mixture of 1) enough differentiated use cases with requirements to sustain specialized capabilities, and 2) less generalizability of innovations (such as training techniques) within these spaces.
The idiosyncrasies of training techniques (pre and post-training) unique to specific modalities is definitely a reason for sustained competition, but the challenge of acquiring high quality training data might be just as key if not more.
In Ben Thompson’s interview with Scale AI CEO Alex Wang, the company’s moat became clear:
Ben Thompson: It strikes as that is actually a pretty significant moat. To the extent that it’s just a really hard and messy problem, if you actually solve those hard and messy problems, no one is going to want to put forth the effort to reinvent the wheel in that regard.
Alex Wang: I remember there’s a slide in one of our early pitch decks where we actually, we just put on a slide a systems design diagram that showed all the little problems that had to be solved and all the little systems that to work together, whether they’re operational or software or all the various systems. Everywhere from how the whole entire quality control mechanism worked to how the entire recruitment machine worked to how the entire performance management system worked to how the entire training system worked, and it was the messiest diagram that you could possibly imagine, and that was actually the point.
In-house labelling efforts are of course underway at most vertical AI application companies, but there is a constant total cost of ownership question when it comes to working with a company like Scale versus taking on the overhead yourself.
For the modalities where data and not compute is the bottleneck, it’s plausible that competition will be fiercer as a larger balance sheet will not bestow the same advantages as in other modalities where simply scaling up compute can help anoint winners. In the long arc of AI, there may well be a convergence where access to compute is the kingmaker.
If that holds, there are several implications for vendors further up the stack.
Applications
The rapidly falling cost of AI inference is well documented - we’re definitely in the penetration pricing phase of AI, where winning market share is paramount for RLHF flywheels to cement market leadership.
But what would the cost curve look like in a few years when there are just one or two research labs scaling frontier models? What if Meta decides that scaling past Llama 3.1’s 405B parameters warrants a divergence from its open source strategy?
In such a future scenario, application builders reliant on the most capable models will have little recourse if model consumption dilutes their margins.
Similar questions could be raised of many vendors that either consume or sell to the foundation model providers.
In theory, the pursuit of AGI ought to sustain a penetration pricing strategy until some definition of AGI is achieved. It’s why Sam Altman has repeatedly argued for lowering the cost of intelligence as being key to more demand and hence AI becoming ubiquitous. In practice, raising the largest ever round of venture financing and aiming for $100bn in revenue and profitability by 2029 may mean a slightly different course.
Thank you for reading. If you liked this piece, please share it with your friends, colleagues, and anyone that wants to get smarter on startup strategy. Subscribe and find me on LinkedIn or Twitter.