



AI GTM: Cloud Prem
Serving Higher Quality Revenue: Non-Tech Enterprises

👋 Hey friends, I’m Akash! Software Synthesis is where I connect the dots on AI, software and company building strategy. You can reach me at akash@earlybird.com!
As the best AI startups grow faster than previous cohorts of SaaS companies, the debate around the quality of the revenue persists.
Given that 60% of enterprise AI spend is coming from innovation budgets, some argue that buyers are simply educating themselves on the technology by working with startups before consolidating around incumbents with data gravity.
Another argument is that most high-flying AI startups are primarily growing with tech scale-ups rather than larger non-tech enterprises (where CIOs have repeatedly expressed a desire to work with existing vendors).
Anshul Ramachandran of Codeium identified these very reasons as why AI startups should aim to be ‘enterprise infrastructure native’ from the earliest stages.
On building for non-tech over the classical Silicon Valley scale-up:
The top 10 US banks employ far more software developers than all of FAANG. And that’s just a handful of banks. And just the US. JPMorgan Chase alone has over 40k technologists.The first argument for non-tech enterprises over tech enterprises is that all of the big tech companies are taking AI very very seriously, and have massive war chests to try to build themselves. It isn’t just the FAANG companies - the availability of open source LLMs and easy-to-use LLM-adjacent frameworks make build more attractive than buy to companies that have the DNA of building.
And all of the big tech companies are trying to capture the market opportunity themselves. Imagine us trying to sell Codeium to Microsoft. Not great.On why non-tech enterprise > consumer:
If you are building a product with generative AI today, the value proposition today is like something about getting more work done or doing more creative work. Enterprises are willing to put big bucks behind that value proposition, and convincing just a few big enterprises will be equivalent to convincing many thousands to tens of thousands of individuals.The constraints needed to serve non-tech enterprises inform product design choices that give startups a right-to-win against incumbents - being enterprise infrastructure native is a decision that’s easier to implement at the earlier stages of a company (as we’ve seen with many companies refactoring code bases and tackling tech debt to move upmarket).
The reason why I call this enterprise infrastructure native and not just enterprise native is to, unsurprisingly, emphasise the infrastructure piece.
The vast majority of additional constraints manifests as technical software infrastructure problems.One of those software infrastructure problems is deploying AI products on-prem.
AI-Driven Repatriation
The trend of larger enterprises repatriating cloud workloads has been underway for years, well before LLMs took hold. The primary driver at the time was economics - at a certain scale, repatriating results in cost savings of over one-third.
A more recent tailwind for repatriation is the realisation that a large proportion of AI productivity gains are powered by access to sensitive company data.

The trend in Morgan Stanley’ CIO surveys showed that non-tech enterprises are definitely planning for a significant % of AI workloads to be in private clouds or on-prem.
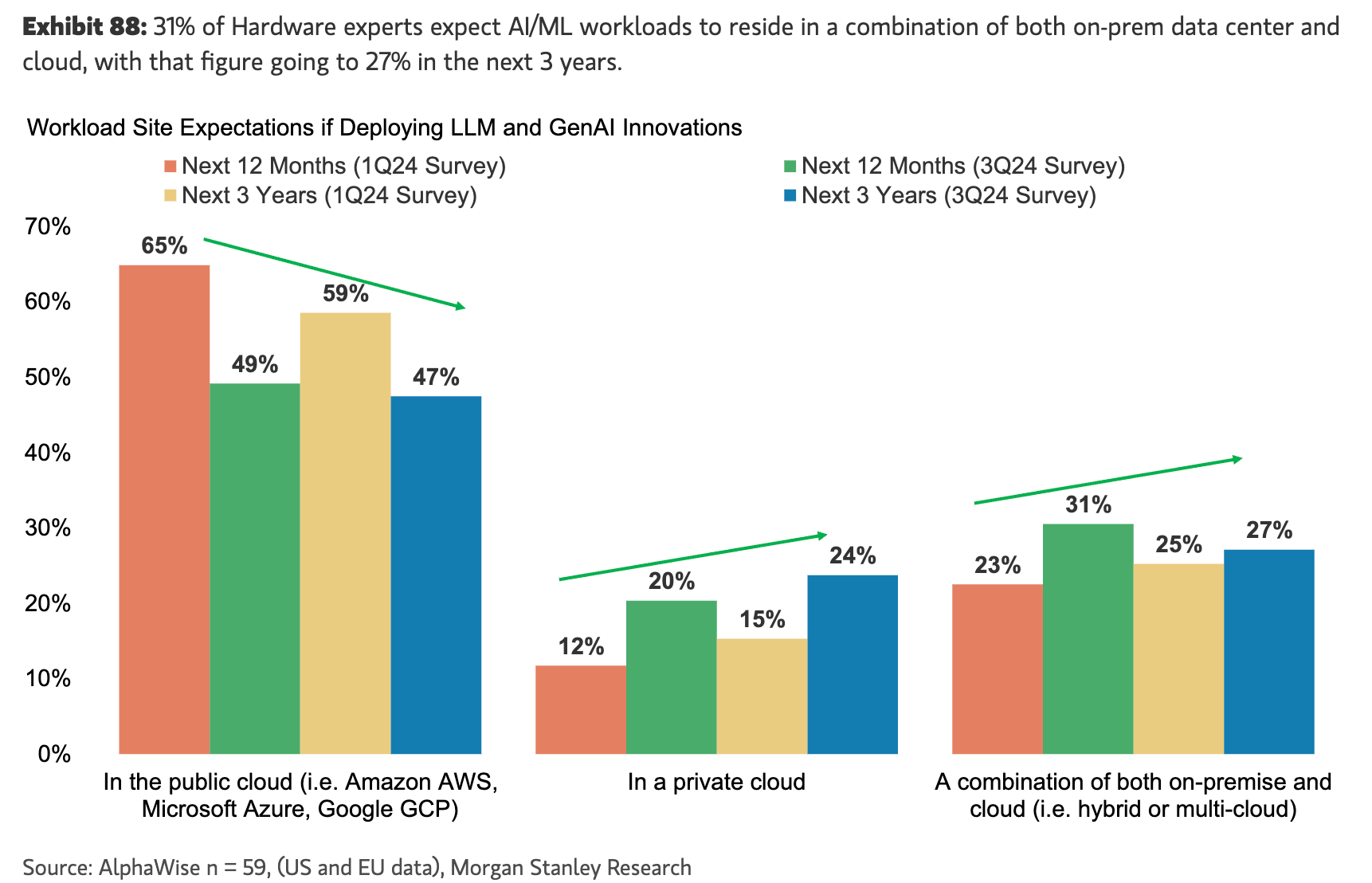
Concerns about data privacy and security ultimately prevail in non-tech enterprises, even if the rational choice is to trust Azure’s security and privacy guarantees over managing your own infrastructure:
Data from Replicated shows that on-premise software continues to grow, even if at a lower CAGR than cloud software - AI deployments will likely be an accelerate for on-prem growth rates..
The merits of the ‘cloud-prem’ architecture have been clear for a while: cost, compliance and control. Here’s Tomasz Tunguz on this shift in 2020:
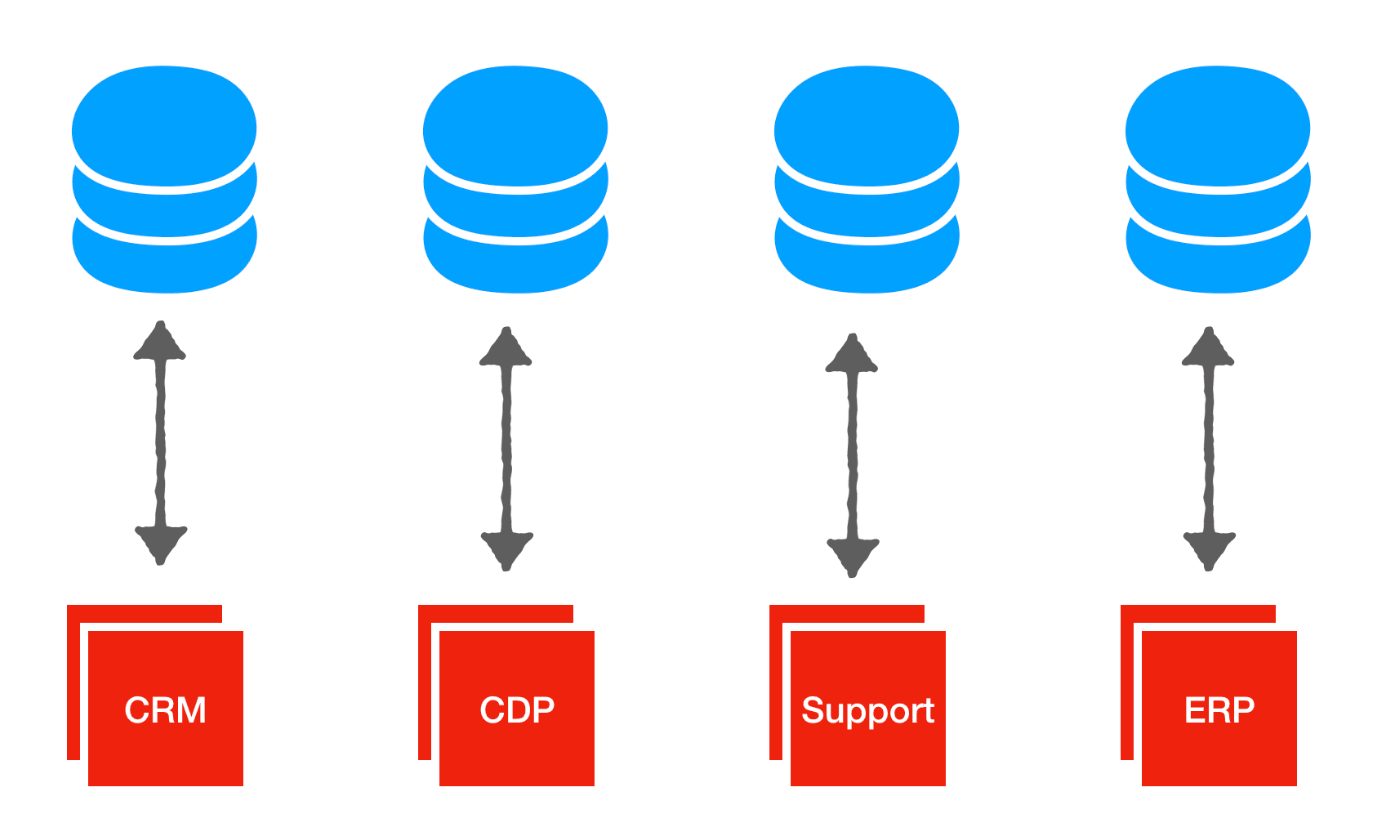
Imagine an enterprise now has several, maybe a dozen applications deployed this way. They won’t have a database for each application. They’ll have one or two. And each piece of software will be pointed to those databases. That’s the twist.In the cloud prem world, the databases are controlled by the customer and accessed by the SaaS product. In the simplest case, the customer has one database. The 12 SaaS products query the database for the data they want to. Each SaaS product is a different cut, filter, or view of that central single data store. It’s a change from point-to-point data to hub-and-spoke data.Credits to Tomasz Tunguz for the before:
And after:
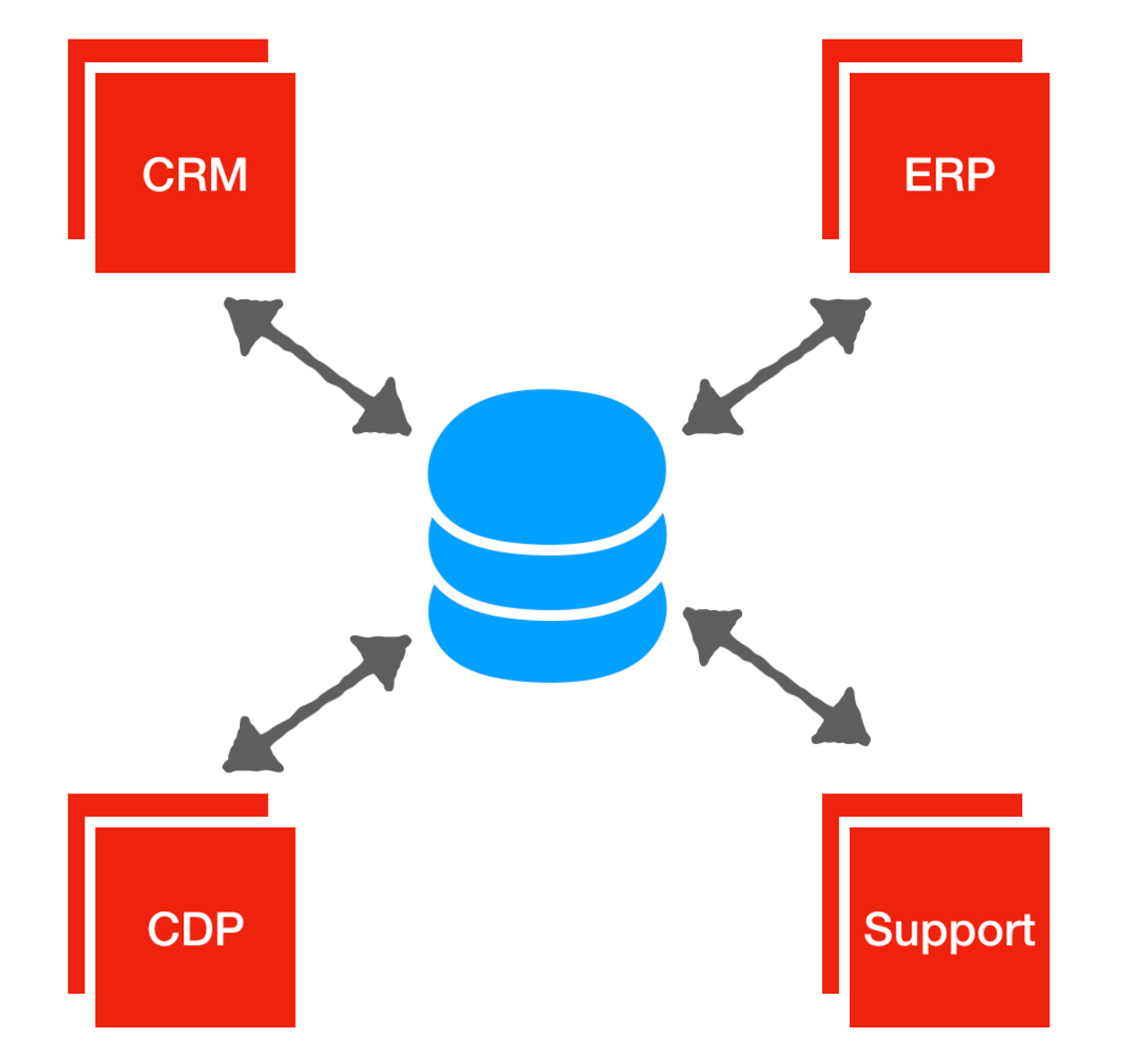
Tomasz wrote about this in 2020 - if you were to replace ‘SaaS products’ with ‘AI agents’, it would completely conform to how most people are describing the future of agentic software:
The 12 SaaS products AI agents query the database for the data they want to. Each SaaS product is a different cut, filter, or view of that central single data store. It’s a change from point-to-point data to hub-and-spoke data.The main issue with this model is version skew - supporting older versions is a big burden for vendors (for this, Anshul suggests faster release cycles to avoid having to do separate patches).
If AI startups want to graduate to higher quality revenue, they’ll need to be cognisant of the growing realisation among buyers that much of the promised ROI in GenAI rests on their precious data. Scenarios of agents having unfettered access to internal databases might be plausible in tech scale-ups, but are completely removed from the reality of procurement in non-tech enterprises.
Architecting products for secure environments (from air-gapped self-hosted versions to single-tenant clouds) is key to higher quality revenues. Please read Anshul’s post for plenty of actionable advice.
Thank you for reading. If you liked this piece, please share it with your friends, colleagues, and anyone that wants to get smarter on AI, startups and strategy. You can find me on LinkedIn or Twitter.
Great post about cloud-prem or BYOC. You should check out Nuon: https://nuon.co/
Very interesting read! Saw this first hand after the release of GPT-3 where major telcos were trying to move sensitive data off cloud infra for AI workloads