


Agent Experience, MCP traction and the end game for Foundation Models
AX > UX and Grok 3's implications for the model layer

Hey friends, I’m Akash! Software Synthesis analyses the evolution of software companies - from how they're built and scaled, to how they go to market and create lasting value. Join thousands of readers that are building, scaling, or investing in software companies. Reach me at akash@earlybird.com to exchange notes.
Agent Experience (AX)
As agent traffic increases, service providers will need to invest as much in AX as they might do in their GUIs and UX.
We’re entering the ‘complex infrastructure’ stage of the AI platform shift, where application/agent developers demand better supply-side infrastructure for tool use.
Basic Infra Phase: We had the creation of core networking infrastructure, including TCP/IP (ARPANET was the predecessor to the Internet in the 70’s / 80’s), early ISPs, the Netscape browser enabling mass internet access, etc. Technology made internet connectivity widely available and set up basic protocols for communication
Basic Application Phase: Early search engines (Google, Yahoo), eCommerce (Amazon, eBay) and email applications. We explored what’s possible with this new infrastructure—basic apps for communication, content, and commerce
Complex Infrastructure Phase: The rise of CDNs (Akamai), broadband, cloud computing (AWS), and security solutions to support more demanding applications. We addressed infrastructure bottlenecks, made the internet faster, more reliable, and capable of supporting more complex applications
Complex Application Phase: The emergence of social networks (Facebook, YouTube, Twitter)), streaming services (Netflix), SaaS platforms, and highly interactive web applications
Jamin BallIt’s plausible that some of the best infrastructure companies will be born out of frustration of application developers, as was the case with the cloud.
Building on this point, there are numerous case studies of transformative infrastructure innovations that were developed internally (and often inadvertently) by builders within app companies. Apache Druid, ClickHouse, Hudi, Iceberg, Presto, and Temporal, are just a few recent examples that come to mind. The origin stories of such technologies demonstrate how “applications inspire infrastructure”, since feedback from the application layer can often drive innovation at the infrastructure layer.
Several project creators have even gone on to found iconic infrastructure companies based on their original inventions. For instance, Confluent (~$12Bn market cap) was initially co-founded by Jay Kreps, Neha Narkhede, and Jun Rao, to commercialize Kafka, a project that they developed at LinkedIn and subsequently open-sourced.
Janelle TengKenneth Auchenberg of AlleyCorp produced an excellent summary of where agent experience infrastructure stands today, with a live map you can update.
Rearchitecting the web for agent traffic will have immediate implications for search and curation, authentication, and caching, as Kojo Osei suggests.
It’ll be interesting to see what kinds of infrastructure companies like Perplexity, Sierra, Cognition and others will develop internally and potentially open source, given that these companies are going to be first-party consumers of messy public and private data. They’ll undoubtedly encounter challenges in scaling their capabilities and the solutions to those infra problems could become standalone companies. Microsoft made GraphRAG open-source to help developers produce more powerful compound AI systems, as one example from the hyperscalers.
MCP Traction
Anthropic’s Model Context Protocol has been in the news since we discussed it last week. Cursor had already rolled out MCP support at the beginning of the month whilst Codeium is releasing content to demonstrate how it enhances Windsurf.
It still has its limitations, of course.
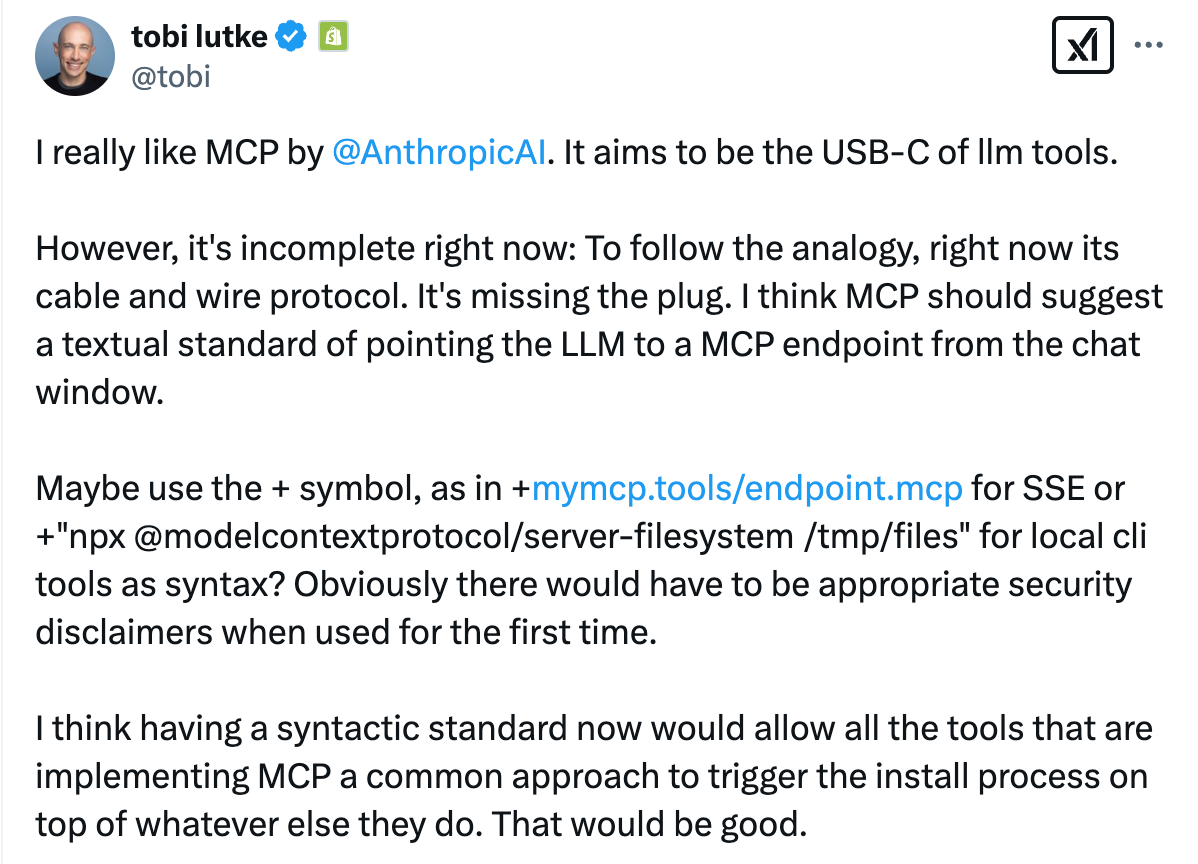
Syntax standardisation would accelerate adoption of the MCP by easing the discovery of MCP servers.
Steve Manuel is also working on MCP server discovery by effectively building an App Store for MCP servers in mcp.run. Users can browse through ‘servlets’ that are compiled to WebAssembly binaries, which means they can be run identically across devices. Wasm modules also achieve faster cold-start times compared to Docker containers, critical for latency-sensitive AI workflows.
The MCP roadmap for this year will be interesting to follow.
The End Game for Foundation Models
The speed at which xAI has caught up to the frontier labs is telling. Within 19 months, xAI released a state of the art model that is right up there with the best reasoning models from OpenAI, Anthropic and Google.
As far as a quick vibe check over ~2 hours this morning, Grok 3 + Thinking feels somewhere around the state of the art territory of OpenAI's strongest models (o1-pro, $200/month), and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking.
Which is quite incredible considering that the team started from scratch ~1 year ago, this timescale to state of the art territory is unprecedented.
Andrej Karpathy.Grok 3’s release has on the one hand reaffirmed faith in the scaling laws and on the other hand cast serious doubt about the current market structure of foundation models.
xAI of course trained Grok 3 on the largest cluster of GPUs ever in Memphis (100,000 GPU data centre). The results are in part attributable to the scaling of compute but perhaps more to proprietary training data.
Google and Xai both have unique, valuable sources of data that will increasingly differentiate them from Deepseek, OpenAI and Anthropic. As does Meta if they catch up from a model capability perspective.
I have paraphrased Eric Vishria many times and noted that frontier models without access to unique, valuable data are the fastest depreciating assets in history. Distillation only amplifies this.
There may not be any ROI on future frontier models that do not have access to unique, valuable data like YouTube, X, TeslaVision, Instagram and Facebook.
Gavin BakerIf the foundation model market consolidates to just 2 or 3 players that have proprietary training data, that has implications for how many giant data centres we need for pre-training, with the rest being for inference. When asked about how Azure’s fleet of data centres can be repurposed, Satya Nadella emphasised agnosticism:
The way I think about it is hey, distributed computing will remain distributed, so go build out your fleet such that it's ready for large training jobs, it's ready for test-time compute, it’s ready - in fact, if this RL thing that might happens, you build one large model, and then after that, there’s tons of RL going on. The frontier labs that don’t possess valuable training data are already becoming product companies to finance their pre-training capex, but is there a world where they completely relinquish the lower levels of the stack and become pure application companies?

X of course now has 611 million MAUs compared to the 368 million at the time of acquisition in 2022.
If Elon Musk follows through on his plans to amass a 1 million GPU cluster, it’ll be hard for other frontier labs to compete but for Google and Meta.
Jobs
Companies in my network are actively looking for talent:
An AI startup founded by repeat unicorn founders and researchers from Meta/Google is building 3D foundation models and is looking for a ML Training / Inference Infrastructure Engineer with 3+ years of experience in a cloud-related role, preferred ML-related (London or Munich).
A Series A company founded by early Revolut employees is building a social shopping platform and is looking for Senior Backend, Frontend and Fullstack Engineers and Business Development Managers across Europe (London, Toronto, France, Germany, Spain, Italy, Remote).
Ex-Revolut team is building a cross-border payments product natively built on stablecoin rails, looking for a Marketing Manager (Spain).
Reach out to me at akash@earlybird.com if you or someone you know is a fit!